
Introduzione all'estrazione di testo
Estrazione del testo - Nel contesto odierno il testo è il mezzo più comune attraverso il quale vengono scambiate le informazioni. Ma comprendere il significato del testo non è affatto un lavoro facile. Abbiamo bisogno di un buon strumento di business intelligence che aiuti a comprendere le informazioni in modo semplice.
Che cos'è l'estrazione di testo
Text Mining è anche noto come Text Analytics. È il processo di comprensione delle informazioni da una serie di testi. Text Mining è progettato per aiutare l'azienda a scoprire preziose conoscenze dal contenuto basato su testo. Questi contenuti possono essere in forma di documento word, e-mail o post sui social media.
L'estrazione del testo è l'uso di metodi automatizzati per comprendere le conoscenze disponibili nei documenti di testo.
L'estrazione del testo può anche essere utilizzata per far comprendere al computer dati strutturati o non strutturati. I dati qualitativi o non strutturati sono dati che non possono essere misurati in termini di numeri. Questi dati di solito contengono informazioni come colore, trama e testo. I dati quantitativi o strutturati sono dati che possono essere misurati facilmente.
Il mining di testo è un campo interdisciplinare che include il recupero di informazioni, il data mining, l'apprendimento automatico, le statistiche e altri. L'estrazione del testo è un campo leggermente diverso dal data mining.
Vantaggi dell'estrazione del testo
Ci sono molti vantaggi nell'utilizzare Text Mining. Sono elencati di seguito
- Risparmia tempo e risorse ed esegue in modo efficiente rispetto al cervello umano.
- Aiuta a tenere traccia delle opinioni nel tempo
- L'estrazione del testo aiuta a sintetizzare i documenti
- L'analisi del testo aiuta a estrarre concetti dal testo e presentarlo in un modo più semplice
- Il testo indicizzato tramite Text mining può essere utilizzato nell'analisi predittiva
- È possibile collegare qualsiasi vocabolario per utilizzare la terminologia nella propria area di interesse
Usi dell'estrazione del testo
- I nomi di diverse entità e relazioni tra il testo possono essere facilmente trovati usando varie tecniche.
- Aiuta a estrarre modelli da una grande quantità di dati non strutturati
- Revisione sistematica della letteratura - Può andare per una ricerca approfondita del testo, scoprire temi chiave ed evidenziare i termini o il testo ripetuti e gli argomenti popolari per un periodo di tempo.
- Verifica dell'ipotesi - Attraverso l'estrazione del testo è possibile verificare un'ipotesi particolare per verificare se il documento conferma o smentisce l'ipotesi. Principalmente una convinzione consolidata viene prima verificata sul documento.
Sviluppa soluzioni ai problemi aziendali in modo efficace. Impara a definire, analizzare e documentare i requisiti aziendali. Indagare sulle attività commerciali per renderle più efficienti.
Importanza dell'estrazione del testo
- Text Mining consente di prendere decisioni migliori e intelligenti
- Aiuta a risolvere i problemi di scoperta della conoscenza in diverse aree di business
- Tramite il mining del testo è possibile visualizzare facilmente i dati in molti modi come tabelle html, grafici, grafici e altri
- È un ottimo strumento di produttività. Dà risultati migliori più velocemente di qualsiasi altro strumento.
- Lo strumento di estrazione del testo viene utilizzato da organizzazioni su larga e piccola scala che sono organizzazioni basate sulla conoscenza.
Applicazioni di estrazione di testo
-
Analizzare le risposte aperte del sondaggio
Le domande a sondaggio aperte aiuteranno gli intervistati a esprimere la propria opinione o opinione senza alcun vincolo. Ciò contribuirà a conoscere meglio le opinioni dei clienti piuttosto che fare affidamento su questionari strutturati. L'estrazione del testo può essere utilizzata per analizzare tali informazioni sotto forma di testo.
-
Elaborazione automatica di messaggi, e-mail
L'estrazione del testo viene anche utilizzata principalmente per classificare il testo. L'estrazione del testo può essere utilizzata per filtrare la posta non necessaria utilizzando determinate parole o frasi. Tali messaggi elimineranno automaticamente tali messaggi come spam. Tale sistema automatico di classificazione e filtraggio delle e-mail selezionate e invio al dipartimento corrispondente viene effettuato utilizzando il sistema di estrazione testo. Text Mining invierà inoltre un avviso all'utente e-mail per rimuovere le e-mail con tali parole o contenuti offensivi.
-
Analisi dei diritti di garanzia o assicurazione
Nella maggior parte delle organizzazioni imprenditoriali le informazioni sono raccolte principalmente sotto forma di testo. Ad esempio in un ospedale le interviste ai pazienti possono essere narrate brevemente in forma testuale e anche i rapporti sono in forma di testo. Queste note sono ora raccolte elettronicamente per un giorno in modo che possano essere facilmente trasferite negli algoritmi di mining del testo. Questi record possono quindi essere utilizzati per diagnosticare la situazione reale.
-
Indagare sulla concorrenza eseguendo la scansione dei loro siti Web
Un'altra importante area di applicazione di Text Mining è l'elaborazione dei contenuti delle pagine Web in un determinato dominio. In questo modo il sistema di estrazione del testo troverà automaticamente un elenco di termini utilizzati nel sito. In questo modo è possibile scoprire i termini più importanti utilizzati nel sito Web. In questo modo si possono conoscere le capacità dei concorrenti che possono aiutarvi a fornire affari in modo efficiente.
Le altre applicazioni di Text Mining includono quanto segue
- Business Intelligence
- E Scoperta
- Bioinformatica
- Gestione dei record
- Funzionalità di sicurezza nazionale o di intelligence
- Monitoraggio dei social media
Tecniche utilizzate nell'estrazione del testo
Esistono cinque tecnologie di base utilizzate nel sistema di estrazione testo. Sono discussi in dettaglio di seguito
-
Estrazione delle informazioni
Questo è usato per analizzare il testo non strutturato scoprendo le parole importanti e trovando le relazioni tra di loro. In questa tecnica il processo di corrispondenza dei modelli viene utilizzato per scoprire l'ordine nel testo. Aiuta a trasformare il testo non strutturato in forma strutturata. La tecnica di estrazione delle informazioni prevede moduli di elaborazione del linguaggio. Viene utilizzato principalmente in presenza di grandi quantità di dati. Il processo di estrazione delle informazioni è spiegato nella figura seguente.
-
categorizzazione
La tecnica di categorizzazione classifica il documento di testo in una o più categorie. Si basa su esempi di output di input per eseguire la classificazione. Il processo di categorizzazione include pre-elaborazione, indicizzazione, riduzione dimensionale e classificazione. Il testo può essere classificato usando tecniche come il classificatore bayesiano naive, l'albero decisionale, il classificatore prossimo più vicino e le macchine del fornitore di supporto.
-
Clustering
Il metodo di clustering viene utilizzato per raggruppare documenti di testo con contenuti simili. Ha partizioni chiamate cluster e ogni partizione avrà un numero di documenti con contenuti simili. Il clustering assicura che dalla ricerca non venga omesso alcun documento e deriva tutti i documenti con contenuti simili. K-medie è la tecnica di clustering usata di frequente. Questa tecnica confronta anche ogni cluster e trova quanto bene il documento è collegato tra loro. Le aziende usano questa tecnica per creare un database con migliaia di documenti simili.
-
visualizzazione
La tecnica di visualizzazione viene utilizzata per semplificare il processo di ricerca delle informazioni pertinenti. Questa tecnica utilizza flag di testo per rappresentare documenti o gruppi di documenti e utilizza i colori per indicare la compattezza. La tecnica di visualizzazione aiuta a visualizzare informazioni testuali in un modo più attraente. L'immagine seguente rappresenterà la tecnica di visualizzazione
-
Summarization
La tecnica di riepilogo aiuterà a ridurre la lunghezza del documento e sintetizzerà i dettagli dei documenti in breve. Fa funzionare il documento in lettura per gli utenti e capisce il contenuto a colpo d'occhio. La sintesi sostituisce l'intera serie di documenti. Riassume in modo semplice e rapido documenti di testo di grandi dimensioni. Gli umani impiegano più tempo a leggere e quindi a riassumere il documento, ma questa tecnica lo rende molto veloce. Aiuta a evidenziare i punti principali di un documento. Il processo di riepilogo è rappresentato nella figura seguente.
Metodi e modelli utilizzati nell'estrazione di testo
Sulla base del recupero delle informazioni, Text Mining ha quattro metodi principali
-
Metodo basato sui termini (TBM)
Termine in un documento significa una parola che ha un significato semantico. Con questo metodo l'intera serie di documenti viene analizzata in base al termine. Uno dei principali svantaggi di questo metodo è il problema della sinonimia e della polisemia. La sinonimia è dove più parole hanno lo stesso significato. Polisemia è dove una singola parola ha più significati.
-
Metodo basato sulla frase (PBM)
In questo metodo il documento viene analizzato sulla base di frasi che sono meno ovvie per più significati e più discriminatorie. Gli svantaggi di questo metodo includono
- Hanno proprietà statistiche inferiori ai termini
- Hanno una bassa frequenza di eventi
- Hanno un gran numero di frasi rumorose
-
Metodo basato sul concetto (CBM)
In questo metodo il documento viene analizzato in base alla frase e al livello del documento. In questo metodo ci sono tre componenti principali. Il primo componente esamina la parte significativa delle frasi. Il secondo componente produce un grafico ontologico concettuale per spiegare le strutture. Il terzo componente estrae i concetti principali in base ai primi due componenti. Questo metodo può distinguere tra parole importanti e non importanti.
-
Pattern Taxonomy Method (PTM)
In questo metodo il documento viene analizzato in base ai modelli. I pattern in un documento possono essere scoperti usando tecniche di data mining come mining di regole di associazione, mining di sequenziali, mining di set di oggetti frequenti e mining di modelli chiusi. Questo metodo utilizza due processi: distribuzione dei modelli e evoluzione dei modelli. Questo metodo ha dimostrato di funzionare meglio di tutti gli altri modelli o metodi.
Come funziona l'estrazione del testo
Ora avresti dovuto capire che l'estrazione del testo consente di capire il testo meglio di ogni altra cosa. Il sistema di mining di testo effettua uno scambio di parole da dati non strutturati in valori numerici. Il mining del testo consente di identificare modelli e relazioni esistenti all'interno di una grande quantità di testo. Il mining di testo spesso utilizza algoritmi computazionali per leggere e analizzare informazioni testuali. Senza il mining del testo sarà difficile capire il testo facilmente e rapidamente. Il testo può essere estratto in modo più sistematico e completo e le informazioni sull'attività possono essere acquisite automaticamente. I passaggi del processo di estrazione del testo sono elencati di seguito.
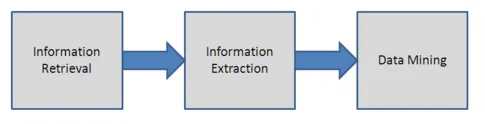
-
Passaggio 1: recupero delle informazioni
Questo è il primo passo nel processo di data mining. Questo passaggio prevede l'aiuto di un motore di ricerca per scoprire la raccolta di testo noto anche come corpus di testi che potrebbe richiedere una conversione. Questi testi dovrebbero anche essere riuniti in un formato particolare che sarà utile per la comprensione da parte degli utenti. Di solito XML è lo standard per il mining di testo
-
Passaggio 2: elaborazione del linguaggio naturale
Questo passaggio consente al sistema di eseguire analisi grammaticale di una frase per leggere il testo. Analizza anche il testo in strutture.
-
Passaggio 3: estrazione delle informazioni
Questa è la seconda fase in cui, al fine di identificare il significato di un particolare mark-up di testo, viene eseguito. In questa fase vengono aggiunti al database dei metadati relativi al testo. Implica anche l'aggiunta di nomi o posizioni al testo. Questo passaggio consente al motore di ricerca di ottenere le informazioni e scoprire le relazioni tra i testi utilizzando i loro metadati.
-
Passaggio 4: Data mining
La fase finale è data mining utilizzando diversi strumenti. Questo passaggio trova le somiglianze tra le informazioni che hanno lo stesso significato che sarebbe altrimenti difficile da trovare. Text Mining è uno strumento che potenzia il processo di ricerca e aiuta a testare le query.
L'estrazione del testo include il seguente elenco di elementi
- Classificazione del testo
- Cluster di testo
- Estrazione concetto / entità
- Tassonomie granulari
- Analisi del sentimento
- Riepilogo dei documenti
- Modellazione di relazioni di entità
Sfide dell'estrazione del testo
La principale sfida affrontata dal sistema di estrazione testo è il linguaggio naturale. Il linguaggio naturale affronta il problema dell'ambiguità. Per ambiguità si intende un termine con diversi significati, una frase interpretata in vari modi e di conseguenza si ottengono significati diversi.
Un'altra limitazione è che durante l'utilizzo del sistema di estrazione delle informazioni comporta l'analisi semantica. Per questo motivo il testo completo non viene presentato, solo una parte limitata del testo viene presentata agli utenti. Ma oggigiorno è necessaria una maggiore comprensione del testo.
Text Mining ha anche delle limitazioni con la legislazione sul copyright. Esistono molte restrizioni nell'estrazione di testo di un documento. Il più delle volte include i diritti dei titolari del copyright. La maggior parte dei testi non sarà trovata come open source e in tali casi sono richieste autorizzazioni dai rispettivi autori, editori e altre parti correlate.
Un'altra limitazione è il mining di testo che non genera nuovi fatti e non è un processo finale.
Conclusione
L'estrazione del testo o l'analisi del testo è una tecnologia in forte espansione, ma i risultati e la profondità dell'analisi variano da azienda a azienda. Un'organizzazione può utilizzare il text mining per acquisire conoscenze sui valori specifici del contenuto.