

Differenza tra Apache Hive e Apache HBase -
La storia di Apache Hive inizia nel 2007 quando il programmatore non Java deve lottare durante l'utilizzo di Hadoop MapReduce. Ricercatori e sviluppatori hanno predetto che domani sarà un'era di Big Data. Già diversi formati di dati come strutturato, semi-strutturato e non strutturato si stavano accumulando. Anche Facebook stava lottando con la maggiore quantità di elaborazione dei dati. I ricercatori di Facebook hanno presentato Apache Hive per l'elaborazione dei dati su Hadoop Cluster. Facebook è stata la prima azienda a presentare Apache Hive.
La storia di Apache HBase inizia nel 2006, quando la startup Powerset con sede a San Francisco stava cercando di costruire un motore di ricerca in linguaggio naturale per il web. HBase è un'implementazione di Bigtable di Google. Ci siamo mai resi conto, perché era necessario creare un'altra architettura di archiviazione? Il sistema di gestione dei database relazionali esiste dai primi anni '70. Esistono molti casi d'uso in cui i database relazionali hanno perfettamente senso, ma per alcuni problemi specifici, il modello relazionale non si adatta molto bene.
Lasciami spiegare in dettaglio Apache Hive e Apache HBase.
Differenze tra Apache Hive e Apache HBase
Apache Hive è un progetto open source Apache basato su Hadoop per eseguire query, riepilogare e analizzare set di dati di grandi dimensioni utilizzando un'interfaccia simile a SQL. Apache Hive offre un linguaggio simile a SQL chiamato HiveQL, che converte in modo trasparente le query in MapReduce per l'esecuzione su set di dati di grandi dimensioni memorizzati in Hadoop Distributed File System (HDFS). Apache Hive è un componente cluster Hadoop che viene normalmente distribuito dagli analisti di dati. L'alveare di Apache viene utilizzato per l'elaborazione batch di grandi lavori ETL. Apache Hive supporta anche query SQL batch su set di dati molto grandi. Apache Hive aumenta la flessibilità di progettazione dello schema e anche la serializzazione e la deserializzazione dei dati. Apache Hive non supporta l'elaborazione delle transazioni online (OLTP) perché hive non supporta le query in tempo reale e gli aggiornamenti a livello di riga.
Apache HBase è un database NoSQL open source che fornisce accesso in tempo reale in lettura e scrittura a set di dati di grandi dimensioni. NoSQL è un database non relazionale. Apache HBase è un database distribuito orientato alla colonna che gira su Hadoop Distributed File System (HDFS). Quindi, HBase porta i vantaggi di NoSQL a Hadoop. Apache HBase offre funzionalità di accesso casuale ai dati presenti in HDFS. Sfrutta la tolleranza ai guasti fornita da HDFS. L'utente può archiviare i dati in HDFS direttamente o tramite HBase.
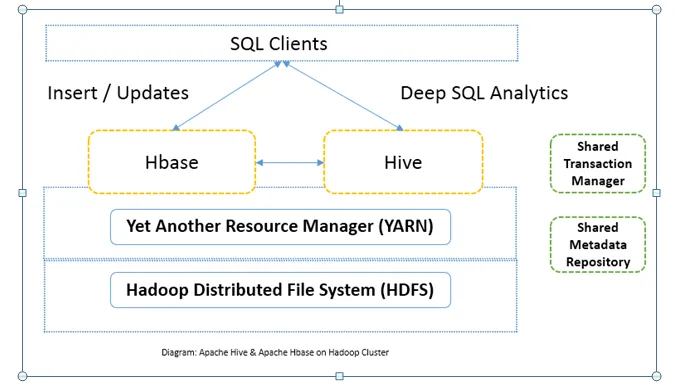
Confronto testa a testa tra Apache Hive e Apache HBase (infografica)
Di seguito è riportata la principale differenza 12 tra Apache Hive e Apache HBase

Differenze chiave - Apache Hive vs Apache HBase
Di seguito sono riportati gli elenchi di punti, descrivono le principali differenze tra Apache Hive e Apache HBase:
- Apache HBase è un database mentre Apache Hive è un motore di database.
- Apache Hive viene utilizzato principalmente per l'elaborazione batch (OLAP) mentre Apache HBase viene utilizzato principalmente per l'elaborazione transazionale (OLTP).
- Apache Hive esegue la maggior parte delle query SQL mentre Apache HBase non consente direttamente le query SQL.
- Apache Hive non supporta operazioni a livello di record come aggiornamento, inserimento ed eliminazione mentre Apache HBase supporta operazioni a livello di record come aggiornamento, inserimento ed eliminazione.
- Apache Hive funziona su MapReduce mentre Apache HBase funziona su Hadoop Distributed File System (HDFS).
Apache Hive interroga i file definendo una tabella virtuale ed eseguendo query HQL su di esso. È un processo in cui i file sono virtualmente connessi a una tabella come la struttura e l'utente può eseguire Hive Query Language (HQL) e queste query vengono convertite in MapReduce Job da Hive. L'utente non deve scrivere il processo MapReduce, le query HQL vengono convertite internamente in file jar e questi file jar verranno implementati su set di dati.
In Apache HBase, le tabelle sono suddivise in regioni e sono servite dai server delle regioni. Altre regioni vengono divise verticalmente in famiglie di colonne in negozi e i negozi vengono salvati come file in HDFS.
Quando usare Apache Hive:
- Requisiti per la conservazione dei dati
- Query analitiche
- Analisi dei dati che hanno familiarità con SQL
Quando usare Apache HBase:
- Elaborazione dati veloce e interattiva
- Query in tempo reale
- Ricerche veloci
- Elaborazione lato server
- Accesso casuale in lettura / scrittura ai Big Data
- Scalabilità dell'applicazione
Apache Hive può essere utilizzato per calcolare tendenze e registri del sito Web di e-commerce per una determinata durata, regione o fuso orario. Può essere utilizzato per elaborare query batch su dati storici, mentre Apache HBase può essere utilizzato da Facebook o LinkedIn per la messaggistica e l'analisi in tempo reale. Può anche essere usato per contare i Mi piace.
Tabella di confronto tra Apache Hive e Apache HBase
Sto discutendo i principali artefatti e distinguendo tra Apache Hive e Apache HBase.
| Apache Hive | Apache HBase | |
| Elaborazione dati | Apache Hive è utilizzato per
elaborazione batch, ad esempio Elaborazione analitica online (OLAP) | Apache HBase viene utilizzato per l'elaborazione transazionale, ad esempio Elaborazione transazionale online (OLTP) |
| Velocità di elaborazione | Apache Hive ha una latenza maggiore a causa dell'esecuzione del processo MapReduce in background | Apache HBase funziona su query in tempo reale e molto più velocemente di Apache Hive |
| Compatibilità con Hadoop | Apache Hive funziona su MapReduce | Apache HBase funziona su HDFS |
| Definizione | Apache Hive è open source e simile a SQL utilizzato per le query analitiche | Apache HBase è un database NoSQL open source utilizzato per le query in tempo reale |
| Metadati condivisi | I dati creati in Apache Hive sono automaticamente visibili ad Apache HBase | I dati creati in Apache HBase sono automaticamente visibili ad Apache Hive |
| Schema | Apache hive supporta Schema per l'inserimento di dati nelle tabelle | Apache HBase è un database privo di schemi. |
| Funzionalità di aggiornamento | La funzione di aggiornamento è complicata in Apache Hive | L'utente può aggiornare molto facilmente i dati in Apache HBase |
| operazioni | Le operazioni in Apache Hive non vengono eseguite in tempo reale | Le operazioni in Apache HBase vengono eseguite in tempo reale |
| Tipi di dati | Apache Hive è pensato per dati strutturati e semi-strutturati | Apache HBase è per dati non strutturati. |
| Livello di coerenza | L'alveare di Apache supporta l'eventuale coerenza | Apache HBase supporta la coerenza immediata |
| Metodi di partizione | Apache Hive supporta le funzioni di frammentazione | Apache HBase supporta anche le funzioni di frammentazione |
| Archivio dati | La data è memorizzata in Hive Metastore, partizioni e bucket in Apache Hive | I dati sono memorizzati in colonne e righe delle tabelle in Apache HBase |
Conclusione - Apache Hive vs Apache HBase
Comunemente Apache Hive vs Apache HBase è usato insieme nello stesso cluster. Entrambi possono essere usati insieme per migliorare la potenza di elaborazione. Poiché l'alveare migliora i lati analitici di HDFS, mentre HBase migliora le transazioni in tempo reale. L'utente può utilizzare Hive come strumento ETL per inserimenti batch con i dati in HBase e quindi eseguire query che possono ulteriormente unire i dati presenti sulle tabelle HBase con i dati già presenti su HDFS. I dati possono essere letti e scritti da Apache Hive su HBase e viceversa. L'interfaccia tra Apache Hive e Apache HBase è ancora in fase di maturazione. Ci sono molte altre cose a venire. Tuttavia, posso dire che sia Apache Hive che Apache HBase rendono il cluster Hadoop più robusto e potente.
Articoli Correlati:
Questa è stata una guida per Apache Hive vs Apache HBase, il loro significato, confronto testa a testa, differenze chiave, tabella di confronto e conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- Le 5 principali tendenze dei Big Data
- 5 sfide di Big Data Analytics
- Come rompere l'intervista allo sviluppatore di Hadoop?
- 5 sfide di Big Data Analytics