

Che cos'è il data mining?
Prima di comprendere i concetti e le tecniche di data mining, studieremo innanzitutto il data mining. Il data mining è una caratteristica della conversione dei dati in alcune informazioni utili. Questo si riferisce al processo di acquisizione di alcune nuove informazioni esaminando una grande quantità di dati disponibili. Utilizzando varie tecniche e strumenti, è possibile prevedere le informazioni richieste dai dati, solo se la procedura seguita è corretta. Ciò è utile in vari settori per estrarre alcune informazioni richieste per analisi future riconoscendo alcuni modelli nei dati esistenti in database, data warehouse, ecc.
Tipi di dati nel data mining
Di seguito sono riportati i tipi di dati su cui è possibile eseguire il data mining:
- Database relazionali
- Data warehouse
- DB avanzati e repository di informazioni
- Database orientati agli oggetti e relazionali agli oggetti
- Database transazionali e spaziali
- Database eterogenei e legacy
- Database multimediale e di streaming
- Database di testo
- Text mining e Web mining
Processo di data mining
Di seguito sono riportati i punti per il processo di data mining:
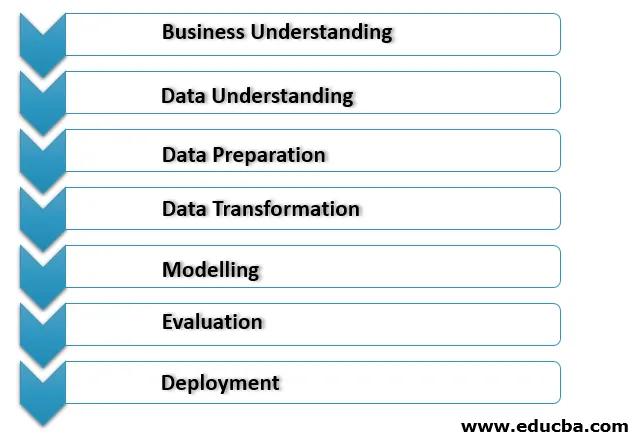
1. Comprensione aziendale
Questa è la prima fase del processo di implementazione del data mining in cui tutte le esigenze e l'obiettivo aziendale del cliente sono chiaramente compresi. Vengono stabiliti obiettivi di data mining adeguati tenendo in considerazione lo scenario attuale nel business e altri fattori come risorse, ipotesi, vincoli. Un piano di data mining adeguato deve essere dettagliato e deve soddisfare i nostri obiettivi aziendali e di data mining.
2. Comprensione dei dati
Questa fase funge da controllo di integrità sui dati che sono stati raccolti da varie risorse per i processi di data mining. Prima di tutto, tutti i dati provenienti da diverse fonti vengono raccolti in relazione allo scenario aziendale dell'organizzazione che può trovarsi nei vari database, file flat, ecc. Viene verificato che i dati raccolti corrispondano correttamente in quanto possono essere inaffidabili.
A volte è necessario verificare anche i metadati per ridurre gli errori nei processi di data mining. Varie query di data mining vengono utilizzate per l'analisi di dati corretti e in base ai risultati è possibile verificare la qualità dei dati. Aiuta anche ad analizzare se mancano dati o meno.
3. Preparazione dei dati
Questo processo consuma il tempo massimo del progetto. Questa faccia include un processo chiamato pulizia dei dati per pulire i dati che sono stati raccolti durante il processo di comprensione dei dati. Il processo di pulizia dei dati viene utilizzato per pulire i dati per escludere dati rumorosi impropri per i dati con valori mancanti.
4. Trasformazione dei dati
Nello stato successivo vengono eseguite operazioni di trasformazione dei dati che vengono utilizzate per modificare i dati per renderli utili per il processo di implementazione del data mining. Qui trasformazione come aggregazione, generalizzazioni, normalizzazione o costruzione di attributi per rendere i dati pronti per il processo di modellazione dei dati.
5. Modellazione
Questa è la fase del data mining in cui viene utilizzata la tecnica corretta per determinare i modelli di dati. I vari scenari devono essere creati per verificare la qualità e la validità di questo modello e per determinare se gli obiettivi che sono stati definiti nel processo di comprensione del business vengono raggiunti dopo l'implementazione di tali tecniche. Il modello che è stato trovato in questo processo viene ulteriormente valutato e inviato per la distribuzione al team operativo aziendale in modo che possa aiutare a migliorare la politica aziendale delle organizzazioni.
6. Valutazione
In questa fase, viene effettuata la corretta valutazione delle scoperte del data mining per provare o meno l'implementazione nei processi aziendali. Viene effettuato un confronto adeguato con le scoperte e il piano operativo esistente per valutare correttamente la modifica delle informazioni trovate che devono essere aggiunte alle operazioni commerciali correnti.
7. Distribuzione
In questa fase, le informazioni che sono state concluse utilizzando i processi di data mining vengono trasformate in forma comprensibile per gli stakeholder non tecnici. Per questo processo, viene creato un piano di implementazione adeguato che include spedizione, manutenzione e monitoraggio delle informazioni trovate. In questo modo, viene creato un rapporto di progetto adeguato insieme alle esperienze e alle lezioni apprese durante il processo per consegnare le nostre scoperte di data mining al team delle operazioni aziendali.
Quindi questo processo aiuta a migliorare la politica aziendale di un'organizzazione.
Tecniche di data mining
Di seguito tecniche e tecnologie possono aiutare ad applicare la funzionalità di data mining nel modo più efficiente:
1. Traccia i motivi
Riconoscere i modelli nel set di dati è una delle tecniche di base nel data mining. I dati vengono osservati a intervalli regolari per il riconoscimento di alcune aberrazioni. Ad esempio, si può vedere se una determinata persona viaggia in diversi paesi, quindi quella persona dovrà prenotare i biglietti su base regolare, quindi può essere offerta una carta di credito speciale.
2. Classificazione
È una delle tecniche complesse per il data mining in cui è necessario creare varie categorie riconoscibili utilizzando vari attributi nei dati esistenti. Queste categorie aiutano a raggiungere varie conclusioni per il nostro uso futuro. Ad esempio, durante l'analisi dei dati relativi al traffico in città, il traffico dell'area può essere classificato come basso, medio e pesante. Ciò aiuterà i viaggiatori a prevedere il traffico prima del tempo.
3. Associazione
Questa tecnica è simile alla tecnica di tracciamento dei modelli, ma qui è correlata alle variabili dipendenti. Ciò significa che viene trovato il modello per i dati correlati collegato ai dati esistenti. L'evento correlato all'altro evento viene tracciato e i modelli particolari si trovano in quei dati. Ad esempio, i dati di tracciamento dei file per il traffico in una città particolare possono anche tracciare, i luoghi più visitati in una città. Questo può anche aiutare a tenere traccia dei luoghi famosi da visitare in città.
4. Rilevamento anomalo
Questa tecnica è correlata all'estrazione di anomalie nel modello di dati. Ad esempio, la vendita di un centro commerciale produce un buon profitto negli 11 mesi dell'anno, ma nell'ultimo mese le vendite sono diminuite tanto da causare perdite. In questi casi, dobbiamo scoprire qual è stato il fattore che ha fatto la riduzione delle vendite in modo da poterlo evitare la prossima volta. La tecnica per trovare una tale distrazione nel modello regolare fa parte della tecnica di rilevamento degli Outlier.
5. Clustering
Questa tecnica è simile alla classificazione, solo la differenza sta nel fatto che raccoglie il gruppo di dati che hanno alcune somiglianze mettendoli in un singolo gruppo. Ad esempio, raggruppando il pubblico diverso di un cinema in base alla frequenza che la frequenza con cui vengono per gli spettacoli, i tempi per cui vengono più spesso e per quale genere di film vengono.
6. Regressione
Questa tecnica aiuta a disegnare la relazione tra le 2 variabili da cui un'analisi potrebbe dipendere. Qui proviamo a scoprire il modello di cambiamento nella variabile fissando le altre variabili dipendenti. Ad esempio, se abbiamo bisogno di scoprire lo schema delle vendite di un prodotto in un centro commerciale a seconda della sua disponibilità, stagione, domanda, ecc. Questo può portare il proprietario a fissare il prezzo per venderlo.
7. Previsione
La caratteristica più importante del data mining è di ridurre i rischi futuri e aumentare il profitto dell'organizzazione studiando i modelli esistenti e storici per i rischi di vendita e di credito. Qui questo tipo di tecnologia ci aiuta a prendere decisioni future a seconda del modello trovato nei dati storici e presenti e tenendo conto del cambiamento del mercato e dei rischi. Questa tecnica è molto utile per il data mining.
Strumenti di data mining
Non sono necessarie le ultime tecnologie per eseguire il data mining. Può essere fatto utilizzando anche i più recenti sistemi di database e strumenti semplici che sono facilmente disponibili in qualsiasi organizzazione. Inoltre, è possibile creare il proprio strumento quando manca lo strumento appropriato. Lo strumento più popolare è ampiamente utilizzato nel settore sono riportati di seguito:
1. R-Language
Questo è uno strumento open source che viene utilizzato per l'elaborazione statistica e la grafica. Questo strumento aiuta a gestire e archiviare i dati in modo efficace e tutte queste funzionalità sono dovute alle seguenti tecniche:
- statistico
- Test statistici classici
- Analisi delle serie storiche
- Classificazione
- Tecniche grafiche
2. Oracle Data Mining
Questo strumento è popolarmente noto come ODM, fa parte del database Oracle Advanced Analytics. Questo strumento aiuta ad analizzare i dati nei data warehouse e genera approfondimenti dettagliati che aiutano ulteriormente a fare previsioni. Queste cose aiutano a studiare il comportamento dei clienti, i prodotti richiedono e quindi aiutano a incrementare le opportunità di vendita.
Sfide da affrontare nell'attuazione della miniera di dati:
- Sono necessari esperti qualificati per eseguire complesse query di data mining.
- I modelli attuali potrebbero non adattarsi ai database degli stati futuri. Potrebbe non adattarsi agli stati futuri.
- Difficoltà incontrate nella gestione di grandi database.
- Potrebbe essere necessario modificare le pratiche commerciali per utilizzare le informazioni che sono state scoperte.
- Database eterogenei e informazioni che arrivano a livello globale possono portare a informazioni integrate complesse.
- Il data mining ha il presupposto che i dati debbano essere di natura diversa, altrimenti i risultati potrebbero essere inaccurati.
Concetti e tecniche di conclusione dei dati
- Il data mining è un modo per tenere traccia dei dati passati e fare analisi future utilizzandoli.
- È uguale all'estrazione delle informazioni richieste per l'analisi dalle risorse dell'ultima data che sono già presenti nei database.
- Il data mining può essere eseguito su vari tipi di database come base di dati spaziali, RDBMS, data warehouse, database multipli e legacy, ecc.
- L'intero processo di mining include comprensione aziendale, comprensione dei dati, preparazione dei dati, modellazione, evoluzione, distribuzione.
- Sono disponibili varie tecniche di data mining per far funzionare il data mining in modo efficiente come classificazione, associazione di regressione, ecc. L'utilizzo dipende dallo scenario.
- Gli strumenti di data mining più efficaci sono R-language e Oracle Data.
- Il principale svantaggio del data mining che si trova ad affrontare sono le difficoltà nella formazione degli esperti per far funzionare quel software di analisi.
- Esistono diversi settori che utilizzano il data mining per i loro scopi di analisi come banche, produzione, supermercati, fornitori di servizi di vendita al dettaglio, ecc.
Articoli consigliati
Questa è una guida ai concetti e alle tecniche di data mining. Qui discutiamo il processo, le tecniche e gli strumenti di data mining in Data Mining. Puoi anche consultare i nostri altri articoli correlati per saperne di più-
- Vantaggi del data mining
- Che cos'è il data mining?
- Processo di data mining
- Tecniche di scienza dei dati
- Clustering in Machine Learning
- Come generare dati di test?
- Guida ai modelli nel data mining