
Panoramica degli algoritmi di rete neurale
- Per prima cosa sappiamo cosa significa una rete neurale? Le reti neurali sono ispirate dalle reti neurali biologiche nel cervello o possiamo dire il sistema nervoso. Ha generato molta eccitazione e la ricerca è ancora in corso su questo sottoinsieme di Machine Learning nell'industria.
- L'unità computazionale di base di una rete neurale è un neurone o un nodo. Riceve valori da altri neuroni e calcola l'output. Ogni nodo / neurone è associato al peso (w). Questo peso è dato secondo l'importanza relativa di quel particolare neurone o nodo.
- Quindi, se prendiamo f come funzione nodo, allora la funzione nodo f fornirà l'output come mostrato di seguito: -
Uscita del neurone (Y) = f (w1.X1 + w2.X2 + b)
- Dove w1 e w2 sono pesi, X1 e X2 sono input numerici mentre b è il bias.
- La precedente funzione f è una funzione non lineare chiamata anche funzione di attivazione. Il suo scopo fondamentale è introdurre la non linearità poiché quasi tutti i dati del mondo reale sono non lineari e vogliamo che i neuroni apprendano queste rappresentazioni.
Diversi algoritmi di rete neurale
Diamo ora un'occhiata a quattro diversi algoritmi di rete neurale.
1. Discesa del gradiente
È uno degli algoritmi di ottimizzazione più popolari nel campo dell'apprendimento automatico. Viene utilizzato durante l'addestramento di un modello di apprendimento automatico. In parole semplici, viene sostanzialmente utilizzato per trovare valori dei coefficienti che riducono semplicemente il più possibile la funzione di costo. Prima di tutto, iniziamo definendo alcuni valori dei parametri e quindi utilizzando il calcolo iniziamo a regolare iterativamente i valori in modo che la funzione persa è ridotta.
Ora, veniamo alla parte che cos'è il gradiente ?. Quindi, un gradiente significa che l'output di qualsiasi funzione cambierà se diminuiamo l'input di poco o in altre parole possiamo chiamarlo alla pendenza. Se la pendenza è ripida, il modello apprenderà più velocemente in modo simile, un modello interrompe l'apprendimento quando la pendenza è zero. Questo perché è un algoritmo di minimizzazione che minimizza un determinato algoritmo.
Sotto la formula per trovare la posizione successiva viene mostrata in caso di discesa gradiente.
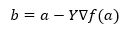
Dove b è la posizione successiva
a è la posizione corrente, gamma è una funzione di attesa.
Quindi, come puoi vedere la discesa del gradiente è una tecnica molto valida, ma ci sono molte aree in cui la discesa del gradiente non funziona correttamente. Di seguito sono riportati alcuni di essi:
- Se l'algoritmo non viene eseguito correttamente, potremmo riscontrare qualcosa di simile al problema del gradiente di scomparsa. Questi si verificano quando il gradiente è troppo piccolo o troppo grande.
- I problemi sorgono quando la disposizione dei dati pone un problema di ottimizzazione non convessa. Il gradiente decente funziona solo con problemi che sono il problema convesso ottimizzato.
- Uno dei fattori molto importanti da cercare durante l'applicazione di questo algoritmo sono le risorse. Se abbiamo meno memoria assegnata per l'applicazione, dovremmo evitare l'algoritmo di discesa gradiente.
2. Metodo di Newton
È un algoritmo di ottimizzazione di secondo ordine. Si chiama un secondo ordine perché utilizza la matrice hessiana. Quindi, la matrice hessiana non è altro che una matrice quadrata di derivate parziali di secondo ordine di una funzione a valore scalare. Nell'algoritmo di ottimizzazione del metodo di Newton, viene applicato alla prima derivata di una doppia funzione differenziabile in modo che possa trovare le radici / punti fissi. Passiamo ora ai passaggi richiesti dal metodo di ottimizzazione di Newton.
Valuta innanzitutto l'indice di perdita. Quindi controlla se il criterio di arresto è vero o falso. Se falso, calcola quindi la direzione di allenamento di Newton e la frequenza di allenamento, quindi migliora i parametri o i pesi del neurone e continua lo stesso ciclo, quindi ora puoi dire che ci vogliono meno passaggi rispetto alla discesa del gradiente per ottenere il minimo valore della funzione. Sebbene comporti meno passaggi rispetto all'algoritmo di discesa gradiente, non è ancora ampiamente utilizzato in quanto il calcolo esatto di iuta e il suo inverso sono computazionalmente molto costosi.
3. Gradiente coniugato
È un metodo che può essere considerato come qualcosa tra la discesa del gradiente e il metodo di Newton. La differenza principale è che accelera la lenta convergenza che generalmente associamo alla discesa del gradiente. Un altro fatto importante è che può essere utilizzato sia per sistemi lineari che non lineari ed è un algoritmo iterativo.
È stato sviluppato da Magnus Hestenes e Eduard Stiefel. Come già accennato in precedenza, produce una convergenza più rapida della discesa del gradiente, il motivo per cui è in grado di farlo è che nell'algoritmo del gradiente coniugato, la ricerca viene eseguita insieme alle direzioni del coniugato, grazie alla quale converge più velocemente degli algoritmi di discesa del gradiente. Un punto importante da notare è che γ è chiamato parametro coniugato.
La direzione dell'allenamento viene periodicamente resettata al negativo del gradiente. Questo metodo è più efficace della discesa gradiente nell'addestramento della rete neurale in quanto non richiede la matrice hessiana che aumenta il carico computazionale e converge più velocemente della discesa gradiente. È opportuno utilizzare in grandi reti neurali.
4. Metodo Quasi-Newton
È un approccio alternativo al metodo di Newton, poiché ora sappiamo che il metodo di Newton è costoso dal punto di vista computazionale. Questo metodo risolve questi inconvenienti in misura tale che invece di calcolare la matrice hessiana e quindi calcolare direttamente l'inverso, questo metodo crea un'approssimazione per invertire l'assia ad ogni iterazione di questo algoritmo.
Ora, questa approssimazione viene calcolata utilizzando le informazioni dalla prima derivata della funzione di perdita. Quindi, possiamo dire che è probabilmente il metodo più adatto per gestire reti di grandi dimensioni poiché consente di risparmiare tempo di calcolo ed è anche molto più veloce della discesa del gradiente o del metodo del gradiente coniugato.
Conclusione
Prima di concludere questo articolo, confrontiamo la velocità di calcolo e la memoria per gli algoritmi sopra menzionati. Secondo i requisiti di memoria, la discesa del gradiente richiede meno memoria ed è anche la più lenta. Al contrario, il metodo di Newton richiede una maggiore potenza computazionale. Quindi, prendendo in considerazione tutto ciò, il metodo Quasi-Newton è il più adatto.
Articoli consigliati
Questa è stata una guida agli algoritmi di rete neurale. Qui discutiamo anche la panoramica dell'algoritmo di rete neurale insieme a quattro diversi algoritmi rispettivamente. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Apprendimento automatico vs rete neurale
- Quadri di apprendimento automatico
- Reti neurali vs apprendimento profondo
- K: significa algoritmo di clustering
- Guida alla classificazione della rete neurale