
Differenza tra Hadoop e Redshift
Hadoop è un framework open source sviluppato da Apache Software Foundation con i suoi principali vantaggi di scalabilità, affidabilità e elaborazione distribuita. Elaborazione dei dati, archiviazione, accesso, sicurezza sono diversi tipi di funzionalità disponibili sull'ecosistema Hadoop. HDFS ha un throughput elevato che significa in grado di gestire grandi quantità di dati con capacità di elaborazione parallela. Redshift è un servizio web di cloud hosting sviluppato dall'unità Amazon Web Services all'interno di Amazon.com Inc., tra i servizi esistenti forniti da Amazon. Viene utilizzato per progettare un data warehouse su larga scala nel cloud. Redshift è un servizio di data warehouse su scala petabyte completamente gestito ed economico per operare su set di dati di grandi dimensioni.
Studiamo di più su Hadoop e Redshift in dettaglio:
Hadoop HDFS ha un'alta capacità di tolleranza agli errori ed è stato progettato per funzionare su sistemi hardware a basso costo. Hadoop può gestire una dimensione minima di tipo da TeraBytes a GigaBytes di file all'interno del suo sistema. HDFS è un'architettura master-slave composta da nodi nome e nodi dati in cui il nodo nome contiene metadati e il nodo dati contiene dati reali da elaborare o utilizzare.
RedShift utilizza diverse tecniche di caricamento dei dati come il reporting BI (Business Intelligence), strumenti analitici e data mining. Redshift fornisce una console per creare e gestire i cluster Amazon Redshift. Il componente principale di Redshift Data Warehouse è un cluster.
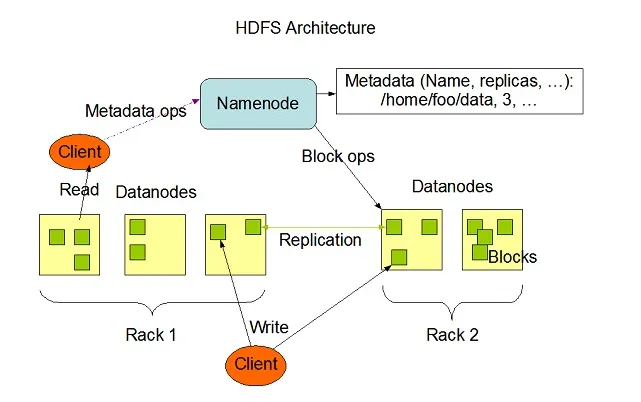
Fonte immagine: Apache.org
Architettura di RedShift:
 Fonte immagine: Amazon.com
Fonte immagine: Amazon.com
Confronto testa a testa tra Hadoop vs Redshift (infografica):
Di seguito sono riportati i primi 10 confronti tra Hadoop e Redshift

Differenze chiave tra Hadoop vs Redshift:
Di seguito sono le differenze chiave tra Hadoop vs Redshift come segue
1. L'architettura Hadoop HDFS (Hadoop Distributed File System) ha nodi nome e nodi dati, mentre Redshift ha nodo Leader e nodi di calcolo in cui i nodi di calcolo verranno partizionati come sezioni.
2. Hadoop fornisce l'interfaccia della riga di comando per interagire con il file system, mentre RedShift ha una console di gestione per interagire con i servizi di archiviazione Amazon come S3, DynamoDB ecc.,
3.Le operazioni del database devono essere configurate dagli sviluppatori. In Redshift automatizza le operazioni del database analizzando i piani di esecuzione.
4.Hadoop ha diversi strumenti di supporto di terze parti da integrare facilmente, mentre Redshift supporta solo i prodotti sviluppati da Amazon nel suo cloud.
5. In termini di progettazione architettonica di Hadoop, rete, archiviazione, sicurezza e prestazioni sono stati considerati elementi primari mentre in Redshift questi elementi possono essere configurati facilmente e in modo flessibile utilizzando la console di gestione del cloud di Amazon.
6.Hadoop è un'architettura di file system basata su API (Application Programming Interface) Java mentre Redshift si basa sul modello relazionale Database Management System (RDBMS).
7.Hadoop può avere integrazioni con diversi fornitori e Redshift non ha supporto in questo caso in cui Amazon è il loro unico fornitore. Cosa succede se un utente non è soddisfatto del servizio? In questo caso, Hadoop è un vantaggio.
8.La maggior parte delle aziende esistenti utilizza ancora Hadoop, mentre i nuovi clienti scelgono RedShift.
9.In termini, le prestazioni di Hadoop mancano sempre e Redshift vince sempre in caso di esecuzione di query su grandi volumi di dati.
10.Hadoop utilizza il modello di programmazione Map Reduce per l'esecuzione dei lavori. Amazon Redshift utilizza Amazon Elastic Map Reduce.
11.Hadoop utilizza il modello di programmazione Map Reduce per l'esecuzione dei lavori. Amazon Redshift utilizza Amazon Elastic Map Reduce.
12.Hadoop è preferibile eseguire quotidianamente lavori batch che diventano più economici, mentre Redshift risulta più economico nel caso della tecnologia OLAP (Online Analytical Processing) esistente dietro molti strumenti di Business Intelligence.
13.Hadoop è 10 volte più lento di Redshift nell'esecuzione di query nello stesso modo in cui Hadoop è 10 volte più costoso di Redshift, con la conseguenza che Hadoop viene scelto meno prima di Redshift.
14. Anche in termini di caricamento dei dati, Hadoop ha supportato Redshift in termini di ore in cui il sistema impiega ore per caricare i dati dalla memoria nel suo sistema di elaborazione dei file.
15.Hadoop può essere utilizzato per archivi a basso costo, archiviazione dei dati, data lake, data warehousing e analisi dei dati, mentre Redshift rientra nelle funzionalità di data warehouse che ne limitano l'utilizzo multiuso.
16.La piattaforma Hadoop fornisce supporto a vari fornitori esterni e ai propri progetti Apache come Storm, Spark, Kafka, Solr ecc. E dall'altro lato Redshift ha un supporto di integrazione limitato con i suoi unici prodotti Amazon
Tabella comparativa Hadoop vs Redshift
| BASE PER
CONFRONTO | HADOOP | REDSHIFT |
| Disponibilità | Framework open source di Apache Projects | Servizi a prezzo forniti da Amazon |
| Implementazione | Fornito da provider Hortonworks e Cloudera ecc., | Sviluppato e fornito da Amazon |
| Prestazione | I lavori di Hadoop MapReduce sono più lenti | Redshift ha prestazioni più veloci rispetto al cluster Hadoop |
| scalabilità | Limitazioni nella scalabilità | Facilmente giù / sovradimensionato secondo il requisito |
| Prezzi | Costa $ 200 al mese per eseguire query | Il prezzo dipende dalla regione del server ed è più economico di Hadoop
Ad esempio: $ 20 / mese |
| Velocità | Più veloce ma più lento rispetto a Redshift | 10 volte più veloce di Hadoop |
| Velocità query | Richiede 1491 secondi per eseguire i dati da 1, 2 TB | 155 secondi per eseguire dati da 1, 2 TB |
| Integrazione dei dati | Flessibile con il file system locale e qualsiasi database | Può caricare dati solo da Amazon S3 o DynamoDB |
| Formato dei dati | Tutti i formati di dati sono supportati | Rigoroso nei formati di dati come i formati di file CSV |
| Facilità d'uso | Complesso e più complicato per gestire le attività amministrative | Gestione automatizzata di backup e data warehouse |
Conclusione - Hadoop vs Redshift
La dichiarazione finale per concludere il grande vincitore in questo confronto è Redshift che vince in termini di facilità di operazioni, manutenzione e produttività, mentre Hadoop manca in termini di scalabilità delle prestazioni e dei costi dei servizi con il solo vantaggio di una facile integrazione con strumenti di terze parti e prodotti. Redshift si è recentemente evoluto con un'enorme crescita e accettazione da parte di molti clienti e clienti grazie alla sua elevata disponibilità e al minor costo delle operazioni rispetto a Hadoop lo rende sempre più popolare. Ma fino ad ora la maggior parte delle aziende Fortune 1000 esistenti hanno utilizzato le piattaforme Hadoop nelle sue architetture per gestire i dati dei clienti.
Nella maggior parte dei casi RedShift è stata la scelta migliore da considerare a fini commerciali da qualsiasi cliente o cliente al fine di gestire i dati grandi e sensibili di qualsiasi istituto finanziario o informazione pubblica con maggiore integrità e sicurezza dei dati.
Oltre a questo, Hadoop ha i suoi vantaggi in quanto progetto open source ed è stato disponibile per molti anni, facendo sì che i sistemi esistenti vengano sostituiti come un processo che comporta costi. Il prodotto dovrebbe essere infine scelto in base ai requisiti e alla flessibilità piuttosto che ai prezzi o alla popolarità in base alle esigenze aziendali guidate.
Articolo raccomandato:
Questa è stata una guida a Hadoop vs Redshift, il loro significato, il confronto testa a testa, le differenze chiave, la tabella di confronto e le conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- Hadoop vs Hive - Scopri le migliori differenze
- HADOOP vs RDBMS | Conosci le 12 differenze utili
- Apache Hadoop vs Apache Spark | I 10 migliori confronti che devi sapere!
- Big Data vs Data Science: come sono diversi?
- Guida su Hadoop vs Spark
- I migliori 4 provider di hosting cloud con funzionalità