

Introduzione a XPath
XPath è un componente principale e principale dello standard XSLT. XPath può essere utilizzato per attraversare elementi, attributi, testo, istruzioni di elaborazione, commenti, spazio dei nomi e documenti in un documento XML (Extensible Markup Language). È una raccomandazione del W3C che contiene una libreria con oltre 200 funzioni integrate. XPath è la sintassi per la definizione di parti di un documento XML. XSLT è il linguaggio dei fogli di stile per i file XML. Con XSLT puoi trasformare documenti XML in altri formati, come XHTML. XQuery riguarda la query di dati XML. XQuery è progettato per eseguire query su tutto ciò che può apparire come XML, inclusi i database. Il collegamento in XML è diviso in due parti: XLink e XPointer. XLink e XPointer definiscono un modo standard di creare collegamenti ipertestuali nei documenti XML.
Espressione di XPath
XPath consente a diversi tipi di espressioni di recuperare informazioni pertinenti dal documento XML. XPath affronta una parte specifica del documento. Modella un documento XML come un albero di nodi. Un'espressione di XPath è una tecnica per navigare e selezionare i nodi dal documento.
Le espressioni XPath possono essere utilizzate in C, C ++, Python, Java, JavaScript, PHP, XML Schema e molte altre lingue. Un'espressione XPath fa riferimento a un modello per selezionare un set di nodi. XPointer utilizza questi schemi per scopi di indirizzamento o per eseguire trasformazioni da XSLT. L'espressione XPath specifica sette tipi di nodi che possono essere il risultato dell'esecuzione.
1. Radice
Elemento radice di un documento XML. Utilizzando i seguenti modi in cui è possibile trovare gli elementi radice.
- Usa carattere jolly (/ *): per selezionare il nodo principale
- Usa nome (/ classe): per selezionare il nodo principale per nome
- Usa nome con un carattere jolly (/ class / *): per selezionare tutti gli elementi nel nodo radice
Codice:
2. Elemento
Nodo elemento di un documento XML. Di seguito sono riportati i modi per trovare l'elemento
- / class / *: usato per selezionare tutti gli elementi nel nodo radice.
- / class / library: usato per selezionare tutti gli elementi della libreria dal nodo radice.
- // libreria: utilizzata per selezionare l'intero elemento della libreria dal documento.
Codice:
3. Attributi
Un attributo di un nodo elemento nel documento XML recuperato e verificato utilizzando il nome dell'attributo @ di un elemento.
Codice:
4. Testo
Testo di un nodo elemento nel documento XML, recuperato e verificato dal nome di un elemento.
Codice:
5. Commento
Esempio di commento
Codice:
Nodo o Elenco del nodo da XML
Di seguito è riportato un elenco di espressioni utili per selezionare un nodo o un elenco del nodo da un documento XML.
- '/': L'utilizzo di questa selezione inizia dal nodo principale.
- '//': l'utilizzo di questa selezione inizia dal nodo corrente che corrisponde alla selezione
- '.': Per selezionare l'attuale espressione utilizzata.
- '..': per selezionare il nodo padre del nodo corrente.
- '@': Per selezionare gli attributi.
Esempio di XPath
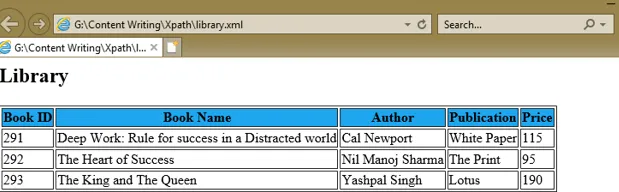
Per comprendere un'espressione XPath, abbiamo creato un documento XML, library.xml e il suo documento del foglio di stile library.xsl che utilizza le espressioni XPath sotto l'attributo select di vari tag XSL per ottenere i valori di ID libro, nome libro, autore, pubblicazione e prezzo di ciascun nodo del libro.
1. library.xml
Codice:
Deep Work: Rule for success in a Distracted world
Cal Newport
White Paper
115
The Heart of Success
Nil Manoj Sharma
The Print
95
The King and The Queen
Yashpal Singh
Lotus
190
2. library.xsl
Codice:
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
| | | | |
|---|---|---|---|---|
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
Produzione:
Vantaggi di XPath
Di seguito sono riportati i vantaggi di Xpath:
- Le query XPath sono semplici da scrivere e da leggere e sono anche compatte.
- La sintassi XPath è semplice per i casi comuni e semplici.
- Le stringhe di query sono integrate in script, programmi e attributi HTML o XML facilmente.
- Le query XPath sono facilmente analizzabili.
- Qualsiasi nodo può riconoscere in modo univoco in un documento XML.
- In un documento XML, è possibile specificare il verificarsi di qualsiasi percorso o insieme di condizioni per i nodi nel percorso.
- Le query restituiscono un numero qualsiasi di risultati, incluso zero.
- In un documento XML, le condizioni della query possono essere calcolate a qualsiasi livello e non devono attraversare dal nodo superiore di un documento XML.
- Le query XPath restituiscono nodi univoci, non nodi ripetuti.
- In molti contesti, XPath viene utilizzato per fornire collegamenti a nodi, per trovare repository e molte altre applicazioni.
- Per i programmatori, le query XPath non sono procedurali ma più dichiarative. Definiscono come attraversare gli elementi. Per ottenere risultati efficienti, gli indici e altre strutture devono essere utilizzati gratuitamente da un Query Optimizer.
Conclusione
XPath è un linguaggio di query utilizzato per attraversare elementi, attributi, testo attraverso un documento XML. XPath è ampiamente utilizzato per trovare elementi o attributi particolari con schemi corrispondenti. Quando viene definita una query, i dati XML possono essere rappresentati come un albero. La rappresentazione gerarchica dei dati XML è chiamata albero. La parte superiore dell'albero è un nodo radice. In un albero, ogni attributo, elementi, testo, commenti, stringa e istruzioni di elaborazione corrispondono a un nodo. Le relazioni tra i nodi possono essere rappresentate dall'albero.
Articoli consigliati
Questa è una guida a Cos'è XPath ?. Qui discutiamo espressione, elenco, esempi e vantaggi di Xpath. Puoi anche consultare i nostri altri articoli correlati per saperne di più-
- Che cos'è XPath in selenio?
- Che cos'è XML?
- Nuovo percorso di carriera
- Percorso di carriera per la sicurezza delle informazioni
- Esempi di funzioni integrate di Python