
Che cos'è Cassandra?
Cassandra è un database NoSQL che è un database distribuito peer-to-peer. Funziona su un cluster che ha nodi omogenei. È realizzato in modo tale da poter gestire grandi volumi di dati. Con la gestione di questi dati dovrebbe anche essere in grado di fornire un'alta capacità. Cassandra offre risultati eccellenti in termini di operazioni di lettura e scrittura. L'architettura del cluster Cassandra non ha padroni, schiavi o leader specifici. Usando questo modo si assicura che non vi sia un singolo punto di errore. Diamo un'occhiata all'architettura in dettaglio.
Architettura di Cassandra
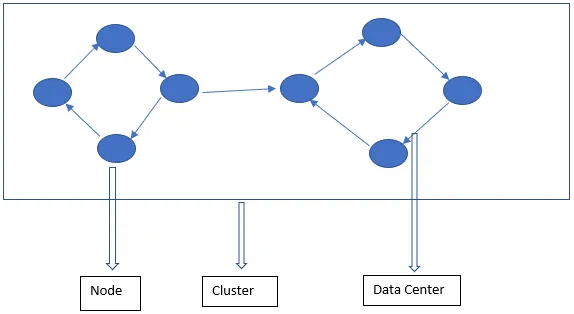
L'architettura Cassandra è costituita principalmente da Nodo, Cluster e Data Center. Oltre a questi, ci sono anche altri componenti. Cassandra è un database archiviato in righe. Consente agli utenti autorizzati di connettersi a qualsiasi nodo in qualsiasi data center utilizzando CQL.
Strutture chiave in Cassandra
Queste sono le seguenti strutture chiave in Cassandra:
- Nodo: qui vengono archiviati i dati. È il componente più basilare di Cassandra. Può essere pensato come un singolo server in un rack. Assicura che non vi sia un singolo punto di errore.
- Data center: un data center è una raccolta di nodi. Questo può essere fisico o virtuale. A seconda del carico di lavoro, i data center vengono divisi e scelti. Il fattore di replica viene deciso sulla base del data center. A seconda di questo fattore di replica, i dati possono essere scritti in diversi data center.
- Cluster: il cluster comprende uno o più data center. I cluster di solito si estendono su posizioni fisiche diverse.
Oltre a questi, gli altri componenti che svolgono un ruolo in Cassandra sono i seguenti.
1. Salva registro
I dati che sono impegnati per mantenere la durata dei dati sono memorizzati nel registro di commit. I dati vengono spostati in una tabella di stringhe ordinata (spiegata in seguito). Una volta eseguito questo spostamento, è possibile archiviare, eliminare o riciclare il registro di commit.
2. Tabella SS
Questa tabella, come menzionato nel punto precedente, memorizza le tabelle di registro o di memoria a intervalli regolari. È un file di dati immutabile. Le tabelle SS possono archiviare frequentemente i dati in modo sequenziale. Aggiungono i dati e mantengono le informazioni per ogni tabella Cassandra.
3. Tabella CQL
La tabella Query Cassandra è una raccolta di colonne ordinate che possono recuperare una riga da questa tabella. In questa tabella sono presenti colonne in cui è possibile recuperare i dati utilizzando la chiave primaria.
4. Filtro Bloom
È un tipo semplice di cache in cui sono memorizzati algoritmi non deterministici per il test. Verifica se un elemento è o meno un membro dell'insieme. Questi filtri sono generalmente accessibili dopo ogni query eseguita.
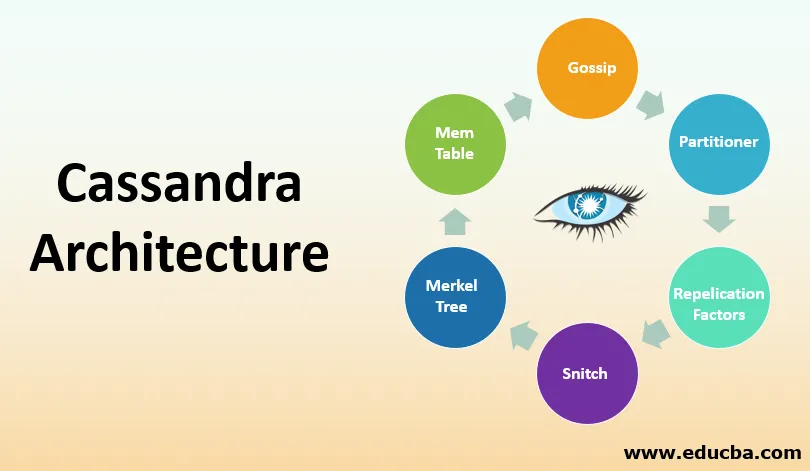
Componenti chiave per configurare Cassandra
Ci sono i seguenti componenti in Cassandra:
1. Gossip
- Come suggerisce il nome, è necessario che vi sia comunicazione tra peer per scoprire e condividere posizione e stato delle informazioni su tutti i nodi.
- Queste informazioni dovrebbero persistere in locale in modo che ciascun nodo possa utilizzare le informazioni non appena un nodo deve riavviarsi. I nodi scoprono informazioni su altri nodi scambiando informazioni.
- Questo può essere fatto per un massimo di tre nodi. Le informazioni non sono condivise con tutti i nodi presenti nel cluster o nel data center. Le informazioni sono condivise con alcuni nodi ma alla fine le informazioni sullo stato attraversano tutto il cluster.
2. Partizionatore
- Il partizionatore decide quale nodo deve ricevere la prima replica di tutti i dati. È anche responsabile della cura della distribuzione di queste repliche.
- Determinerà quale nodo dovrebbe avere quale replica nel cluster. Ogni riga di dati deve essere identificata in modo univoco. Questo può essere fatto usando una chiave primaria o una chiave di partizione.
- Il partizionatore è una funzione hash che aiuta a ottenere un token da una chiave primaria di qualsiasi riga. A ciascun nodo è assegnato un valore num_token che può essere impostato come partizionatore.
- Il valore token generato aiuta a determinare quale nodo riceve la replica delle righe.
3. Fattore di replica
- Questo fattore determina il numero totale di repliche presenti nel cluster. Se il fattore di replica è 1, allora c'è solo una copia di ogni riga su un nodo.
- Allo stesso modo, se il fattore di replica è due, saranno mantenute due copie in cui ogni copia è presente su un nodo diverso. Come accennato in precedenza, non esiste un'architettura master-slave in Cassandra, ogni copia è importante.
- Il fattore di replica è definito per ogni data center. Questo fattore dovrebbe essere maggiore di uno ma non superiore al numero di nodi presenti nel cluster.
4. Spuntino
- La strategia di replica che aiuta a trovare il luogo in cui devono essere posizionate le repliche per un gruppo di macchine nel data center e nel rack è nota come Snitch.
- Esiste un livello dinamico che aiuta nel monitoraggio e nelle prestazioni e aiuta nella scelta della migliore replica da cui è possibile leggere i dati. Gli snitch devono essere configurati solo quando viene creato un cluster.
- Ha valori predefiniti abilitati per la maggior parte delle distribuzioni. Le modifiche alla configurazione possono essere apportate nel file Cassandra.yml in cui è presente la soglia di controllo dinamico per ciascun nodo.
5. Albero di Merkle
- Possono esserci differenze nei blocchi di dati. Per trovare facilmente le differenze, l'albero di Merkle è un albero di hash che aiuta a farlo.
- I nodi foglia dell'albero hash contengono hash di blocchi di dati separati e i nodi padre hanno le informazioni o archiviano anche gli hash dei loro figli.
- Usando questa tecnica è più facile trovare differenze tra i nodi presenti.
6. Tabella mem
- Questa tabella contiene informazioni sulla cache i cui dati non sono ancora stati scaricati e risiedono nella memoria.
Conclusione
Cassandra è un database NoSQL utile per l'elaborazione di enormi quantità di dati. Non ha una tipica architettura master-slave e quindi tutti i nodi sono ugualmente importanti. I nodi hanno repliche in tutto il cluster in base al fattore di replica. Ciò garantisce la coerenza e la durata dei dati. Con tutte queste caratteristiche è chiaro che Cassandra è molto utile per i big data. Cassandra è quindi resistente, veloce in quanto distribuito e affidabile.
Articoli consigliati
Questa è una guida per Cassandra Architecture. Qui discutiamo l'introduzione, l'architettura Cassandra, la struttura chiave e i componenti chiave di Cassandra. Puoi anche consultare i nostri altri articoli suggeriti:
- Panoramica di Kubernetes Architecture
- Che cos'è l'architettura dei Big Data?
- Funzionalità aggiunte ad AutoCAD Architecture
- Architettura di cloud computing