

Panoramica delle applicazioni Kafka
Uno dei settori di tendenza nel settore IT è Big Data, in cui l'azienda gestisce una grande quantità di dati dei clienti e ricava informazioni utili che aiutano la loro attività e forniscono ai clienti un servizio migliore. Una delle sfide è gestire e trasferire questi grandi volumi di dati da un'estremità all'altra per analisi o elaborazione, è qui che entra in gioco Kafka (un sistema di messaggistica affidabile), che aiuta nella raccolta e nel trasporto di enormi volumi di dati in tempo reale. Kafka è progettato per sistemi distribuiti ad alto rendimento ed è adatto per applicazioni di elaborazione di messaggi su larga scala. Kafka supporta molte delle migliori applicazioni commerciali e industriali di oggi. C'è una richiesta per i professionisti di Kafka che hanno forti capacità e conoscenze pratiche.
In questo articolo, impareremo a conoscere Kafka, le sue caratteristiche, i casi d'uso e comprenderemo alcune importanti applicazioni in cui viene utilizzato.
Che cos'è Kafka?
Apache Kafka è stato sviluppato su LinkedIn e successivamente è diventato un progetto Apache open source. Apache Kafka è un sistema di messaggistica veloce, tollerante agli errori, scalabile e distribuito che consente la comunicazione tra due entità, cioè tra produttori (generatore del messaggio) e consumatori (destinatario del messaggio) utilizzando argomenti basati sul messaggio e fornisce una piattaforma per la gestione di tutti i feed di dati in tempo reale.
Le caratteristiche che rendono Apache Kafka migliore di altri sistemi di messaggistica e applicabili ai sistemi in tempo reale sono la sua elevata disponibilità, il ripristino immediato e automatico dagli errori del nodo e supporta la consegna di messaggi a bassa latenza. Queste caratteristiche di Apache Kafka aiutano a integrarlo con i sistemi di dati su larga scala e lo rendono un componente ideale per la comunicazione. 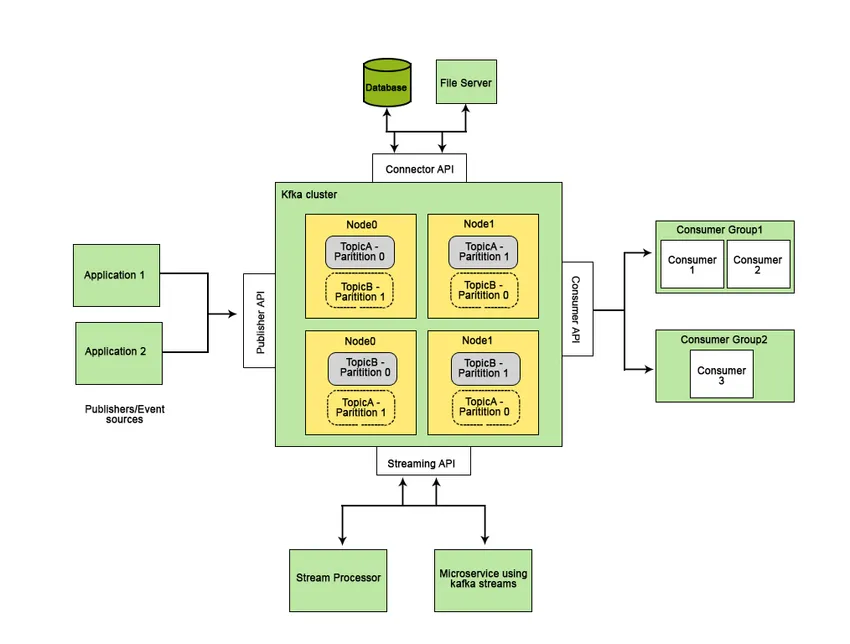
Le migliori applicazioni Kafka
In questa sezione dell'articolo, vedremo alcuni casi d'uso popolari e ampiamente implementati e vedremo l'implementazione nella vita reale di Kafka.
Applicazioni nella vita reale
1. Twitter: attività di elaborazione streaming
Twitter è una piattaforma di social network che utilizza Storm-Kafka (strumento di elaborazione di flussi open source) come parte della propria infrastruttura di elaborazione di flussi, in cui i dati di input (tweet) vengono consumati per aggregazione, trasformazioni e arricchimento per ulteriori consumi o follow-up attività di elaborazione.
2. LinkedIn: elaborazione del flusso e metriche
LinkedIn utilizza Kafka per lo streaming di dati e per l'attività di metriche operative. LinkedIn utilizza Kafka per le sue funzionalità aggiuntive come Newsfeed per consumare messaggi ed eseguire analisi sui dati ricevuti.
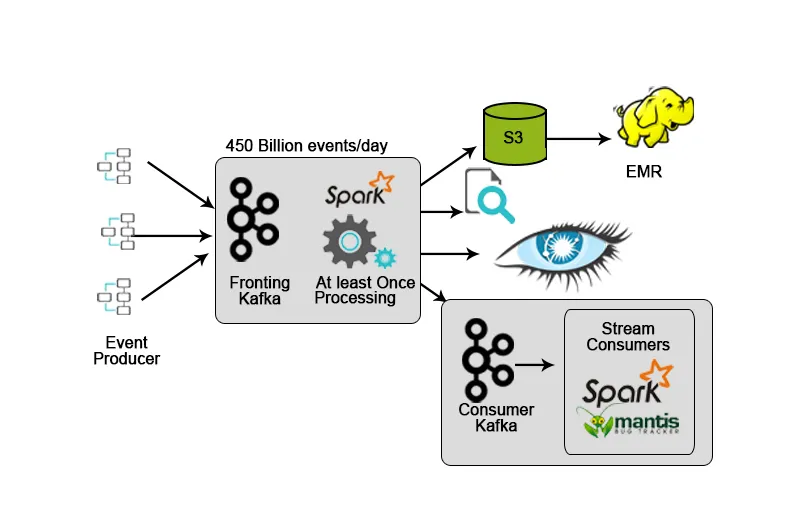
3. Netflix: monitoraggio in tempo reale e elaborazione dei flussi
Netflix ha un proprio framework di importazione che scarica i dati di input in AWS S3 e utilizza Hadoop per eseguire analisi di flussi video, attività dell'interfaccia utente, eventi per migliorare l'esperienza dell'utente e Kafka per l'immissione di dati in tempo reale tramite API.
4. Hotstar: elaborazione stream
Hotstar ha introdotto la propria piattaforma di gestione dei dati, Bifrost, in cui Kafka viene utilizzato per lo streaming, il monitoraggio e il tracciamento dei dati. A causa della sua scalabilità, disponibilità e capacità a bassa latenza, Kafka è stata la scelta ideale per gestire i dati generati dalla piattaforma hotstar su base giornaliera o in qualsiasi occasione speciale (streaming live di qualsiasi concerto o partita di sport dal vivo, ecc.) In cui il volume di dati aumenta in modo significativo.
Apache Kafka viene spesso utilizzato come blocco predefinito per sviluppare l'architettura dei dati di streaming. Questo tipo di architettura viene utilizzata in applicazioni come una raccolta di registri di prodotti / server, analisi di clickstream e derivazione di informazioni da dati generati dalla macchina.
Ma insieme a Kafka, dobbiamo usare risorse o strumenti aggiuntivi per convertire il flusso di dati ottenuto in dati significativi che aiutano a ottenere informazioni che possono essere utilizzate nelle decisioni basate sui dati. Ad esempio, potremmo aver bisogno di generare approfondimenti dai dati grezzi ottenuti dai dispositivi IoT o dai dati ottenuti dalle piattaforme di social media in tempo reale ed eseguire alcune analisi o elaborazioni e mostrarle all'azienda per prendere decisioni migliori o aiutarle a migliorare le prestazioni dei loro servizi.
Per questi tipi di casi d'uso, vorremmo trasmettere i nostri dati di input / dati grezzi in un data lake, dove possiamo archiviare i nostri dati e garantire la qualità dei dati senza ostacolare le prestazioni.
Una situazione diversa, potremmo leggere i dati direttamente da Kafka, è quando abbiamo bisogno di una latenza end-to-end estremamente bassa, come l'invio di dati ad applicazioni in tempo reale.
Kafka presenta alcune funzionalità ai suoi utenti:
- Pubblica e iscriviti ai dati.
- Archivia i dati nell'ordine in cui sono stati generati in modo efficiente.
- Elaborazione dei dati in tempo reale / al volo.
Kafka il più delle volte viene utilizzato per:
- Implementazione di pipeline di dati di streaming al volo che ottengono in modo affidabile dati tra due entità nel sistema.
- Implementazione di applicazioni di streaming al volo che trasformano, manipolano o elaborano i flussi di dati.
Casi d'uso
Di seguito sono riportati alcuni casi d'uso ampiamente implementati dell'applicazione Kafka:
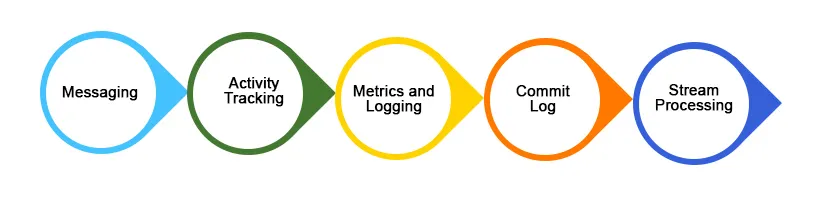
1. Messaggi
Kafka funziona meglio di altri sistemi di messaggistica tradizionali come ActiveMQ, RabbitMQ, ecc. In confronto, Kafka offre un throughput migliore, funzionalità di partizione integrata, funzionalità di replica e tolleranza agli errori, che lo rende un sistema di messaggistica migliore per applicazioni di elaborazione su larga scala .
2. Monitoraggio dell'attività del sito Web
Le attività degli utenti (visualizzazioni di pagina, ricerche o qualsiasi azione eseguita) possono essere monitorate e alimentate per il monitoraggio o l'analisi in tempo reale tramite Kafka o utilizzare Kafka per archiviare questi tipi di dati in Hadoop o data warehouse per successive elaborazioni o manipolazioni. Il rilevamento delle attività genera un'enorme quantità di dati che devono essere trasferiti nella posizione desiderata senza alcun tipo di perdita di dati.
3. Aggregazione dei registri
L'aggregazione dei registri è un processo di raccolta / unione di file di registro fisici da diversi server di un'applicazione in un singolo repository (file server o HDFS) per l'elaborazione. Kafka offre buone prestazioni, una latenza end-to-end inferiore rispetto a Flume.

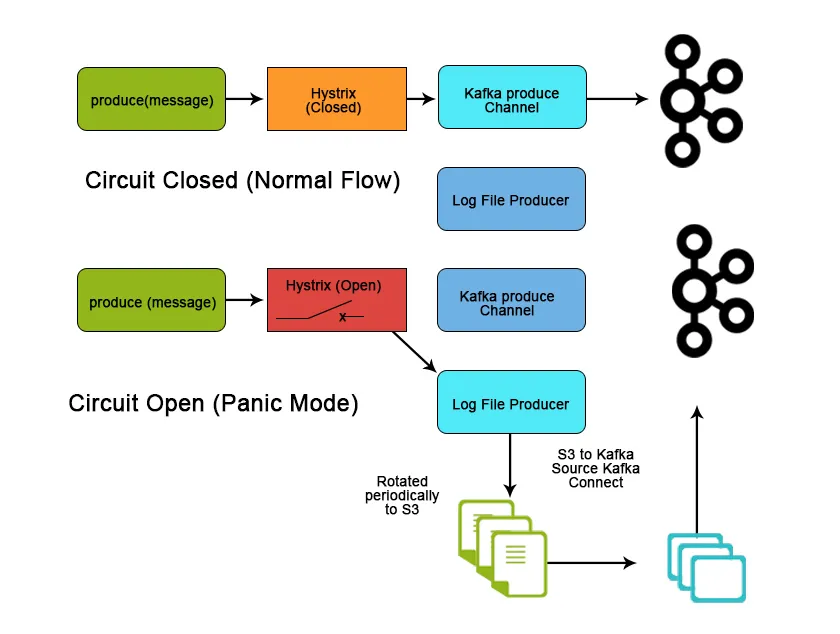
Conclusione
Kafka è ampiamente utilizzato nello spazio dei big data come modo per importare e spostare grandi quantità di dati molto rapidamente a causa delle sue caratteristiche prestazionali e caratteristiche che aiutano a raggiungere scalabilità, affidabilità e sostenibilità. In questo articolo, abbiamo discusso di Apache Kafka le sue funzionalità, i casi d'uso e l'applicazione e ciò che lo rende uno strumento migliore per lo streaming di dati.
Articoli consigliati
Questa è una guida alle applicazioni Kafka. Qui discutiamo cos'è Kafka insieme alle migliori applicazioni di Kafka che includono casi d'uso ampiamente implementati e alcune implementazioni nella vita reale. Puoi anche consultare i seguenti articoli per saperne di più-
- Che cos'è Kafka?
- Come installare Kafka?
- Domande di intervista a Kafka
- Apache Kafka vs Flume
- I 8 principali dispositivi dell'IoT che dovresti sapere
- Kafka vs Kinesis | Differenze con l'infografica
- Diversi tipi di strumenti Kafka con componenti
- Scopri le principali differenze tra ActiveMQ e Kafka