
Differenze tra data scientist e machine learning
Uno scienziato di dati è un esperto responsabile della raccolta, dell'esame e dell'interpretazione di grandi volumi di dati per riconoscere i modi per aiutare un'azienda a migliorare le operazioni e ottenere un vantaggio praticabile rispetto ai concorrenti. Segue un approccio interdisciplinare. Si trova tra la connessione di matematica, statistica, ingegneria del software, intelligenza artificiale e pensiero progettuale. Si occupa di raccolta dati, pulizia, analisi, visualizzazione, modello di validazione, previsione di esperimenti, progettazione, test e ipotesi. L'apprendimento automatico è una divisione dell'intelligenza artificiale che viene utilizzata dalla scienza dei dati per raggiungere i suoi obiettivi. L'apprendimento automatico si concentra principalmente su algoritmi, strutture polinomiali e aggiunta di parole. Consiste in un gruppo di algoritmi, macchine e che consente loro di apprendere senza essere chiaramente programmati per questo.
Data Scientist
Questo ruolo di Data Scientist è una branca del ruolo delle statistiche che include l'uso della versione avanzata delle tecnologie di analisi, incluso l'apprendimento automatico e la modellazione predittiva, per fornire visioni oltre l'analisi statistica. La richiesta di competenze in scienze dei dati è cresciuta in modo significativo negli ultimi anni, poiché le aziende cercano di raccogliere informazioni utili dalle enormi quantità di dati strutturati, semi-strutturati e non strutturati che una grande azienda produce e collettivamente denominati big data. L'obiettivo di tutti i passaggi è solo quello di ricavare intuizioni dai dati.
Attività standard:
- Allocare, aggregare e sintetizzare dati da varie fonti strutturate e non strutturate
- Esplora, sviluppa e applica l'apprendimento intelligente ai dati del mondo reale, fornisci risultati importanti e azioni di successo basate su di essi
- Analizzare e fornire i dati raccolti nell'organizzazione
- Progetta e costruisci nuovi processi per la modellazione, il data mining e l'implementazione
- Sviluppa prototipi, algoritmi, modelli predittivi, prototipi
- Effettuare richieste di analisi dei dati e comunicare i loro risultati e decisioni
Inoltre, ci sono compiti più specifici a seconda del dominio in cui il datore di lavoro sta lavorando o il progetto è in fase di attuazione.
Dati non elaborati -> Data Science --> Informazioni utili
Apprendimento automatico
La posizione di Machine Learning Engineer è più "tecnica". ML Engineer ha più cose in comune con la classica ingegneria del software che con Data Scientist. Ti aiuta a imparare la funzione obiettivo che traccia gli input per la variabile target e / o variabili indipendenti per le variabili dipendenti.
I compiti standard di ML Engineer sono generalmente come Data Scientist. Devi anche essere in grado di lavorare con i dati, sperimentare vari algoritmi di Machine Learning che risolveranno l'attività, creeranno prototipi e soluzioni pronte.
Le conoscenze e le competenze richieste per questa posizione si sovrappongono anche a Data Scientist. Tra le differenze chiave, vorrei individuare:
- Forti capacità di programmazione in uno o più linguaggi popolari (di solito Python e Java), nonché nei database;
- Meno enfasi sulla capacità di lavorare in ambienti di analisi dei dati, ma maggiore enfasi sugli algoritmi di Machine Learning;
- R e Python per la modellazione sono preferibili a Matlab, SPSS e SAS;
- Possibilità di utilizzare librerie già pronte per vari stack nell'applicazione, ad esempio Mahout, Lucene per Java, NumPy / SciPy per Python;
- Capacità di creare applicazioni distribuite utilizzando Hadoop e altre soluzioni.
Come puoi vedere, la posizione di ML Engineer (o più ristretta) richiede maggiori conoscenze in Ingegneria del Software e, di conseguenza, è adatta per sviluppatori esperti. Molto spesso, il caso funziona quando il solito sviluppatore deve risolvere l'attività ML per il suo dovere e inizia a comprendere gli algoritmi e le librerie necessari.
Confronto diretto tra data scientist e machine learning
Di seguito sono riportate le 5 principali differenze tra Data Scientist e Machine Learning engineer 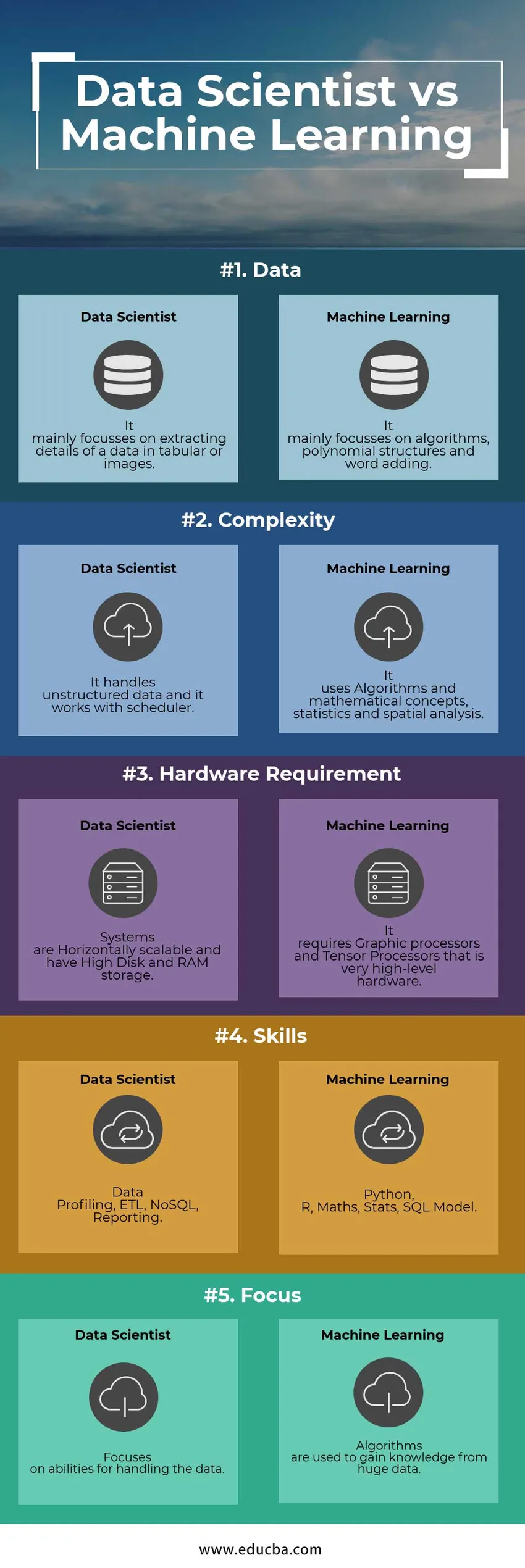
Differenza chiave tra data scientist e machine learning
Di seguito sono elencati gli elenchi di punti, descrivono le principali differenze tra Data Scientist e Machine Learning engineer
- L'apprendimento automatico e le statistiche fanno parte della scienza dei dati. La parola apprendimento nell'apprendimento automatico significa che gli algoritmi dipendono da alcuni dati, usati come set di addestramento, per mettere a punto alcuni parametri di modello o algoritmo. Ciò comprende molte tecniche come la regressione, Bayes ingenuo o il clustering supervisionato. Ma non tutte le tecniche rientrano in questa categoria. Ad esempio, il clustering senza supervisione - una tecnica statistica e di scienza dei dati - mira a rilevare cluster e strutture di cluster senza alcuna conoscenza preliminare o set di formazione per aiutare l'algoritmo di classificazione. È necessario un essere umano per etichettare i cluster trovati. Alcune tecniche sono ibride, come la classificazione semi-supervisionata. Alcune tecniche di rilevamento del modello o di stima della densità rientrano in questa categoria.
- Tuttavia, la scienza dei dati è molto più che apprendimento automatico. I dati, nella scienza dei dati, possono o no provenire da un processo meccanico o meccanico (i dati del sondaggio potrebbero essere raccolti manualmente, le sperimentazioni cliniche coinvolgono un tipo specifico di piccoli dati) e potrebbero non avere nulla a che fare con l'apprendimento come ho appena discusso. Ma la differenza principale sta nel fatto che la scienza dei dati copre l'intero spettro dell'elaborazione dei dati, non solo gli aspetti algoritmici o statistici. La scienza dei dati copre anche l'integrazione dei dati, l'architettura distribuita, l'apprendimento automatico automatizzato, la visualizzazione dei dati, i dashboard e l'ingegneria dei big data.
Data Scientist vs Machine Learning Tabella comparativa
Di seguito sono riportati gli elenchi di punti, descrivono i confronti tra Data Scientist e Machine Learning engineer:
| caratteristica | Data Scientist | Apprendimento automatico |
| Dati | Si concentra principalmente sull'estrazione di dettagli di dati in tabulari o immagini | Si concentra principalmente su algoritmi, strutture polinomiali e aggiunta di parole |
| Complessità | Gestisce dati non strutturati e funziona con lo scheduler | Utilizza algoritmi e concetti matematici, statistiche e analisi spaziali |
| Requisiti hardware | I sistemi sono scalabili orizzontalmente e dispongono di memoria disco e RAM elevata | Richiede processori grafici e processori tensore che sono hardware di altissimo livello |
| Competenze | Profilazione dei dati, ETL, NoSQL, Reporting | Python, R, matematica, statistiche, modello SQL |
| Messa a fuoco | Si concentra sulle capacità di gestione dei dati | Gli algoritmi vengono utilizzati per acquisire conoscenze da enormi dati |
Conclusione - Data Scientist vs Machine Learning
L'apprendimento automatico consente di apprendere la funzione obiettivo che traccia gli input per la variabile target e / o variabili indipendenti per le variabili dipendenti
Uno scienziato di dati fa molta esplorazione dei dati e arriva all'ampia strategia su come affrontarli. È responsabile per porre domande all'interno dei dati e trovare quali risposte si possono ragionevolmente trarre dai dati. L'ingegneria delle caratteristiche appartiene al regno di Data Scientist. Anche la creatività gioca un ruolo qui e un ingegnere di Machine Learning conosce più strumenti e può costruire modelli dati una serie di funzionalità e dati, secondo le indicazioni dello scienziato dei dati. Il regno della pre-elaborazione dei dati e dell'estrazione delle caratteristiche appartiene all'ingegnere ML.
La scienza e l'esame dei dati utilizzano l'apprendimento automatico per questo tipo di convalida e creazione archetipiche. È fondamentale notare che tutti gli algoritmi nella creazione di questo modello potrebbero non provenire dall'apprendimento automatico. Possono arrivare da numerosi altri campi. Il modello desidera essere sempre rilevante. Se le situazioni cambiano, il modello che abbiamo creato in precedenza potrebbe diventare irrilevante. I requisiti del modello devono essere verificati per la loro certezza in momenti diversi e devono essere adattati se la sua certezza si riduce.
La scienza dei dati è un grande dominio. Se proviamo a metterlo in una pipeline avrebbe acquisizione dei dati, memorizzazione dei dati, preelaborazione dei dati o pulizia dei dati, modelli di apprendimento dei dati (tramite machine learning), usando l'apprendimento per le previsioni. Questo è un modo per capire come l'apprendimento automatico si adatta alla scienza dei dati.
Articolo raccomandato
Questa è stata una guida alle differenze tra scienziato dei dati e ingegnere dell'apprendimento automatico, il loro significato, il confronto diretto, le differenze chiave, la tabella di confronto e le conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- Data mining e machine learning - 10 cose migliori che devi sapere
- Apprendimento automatico e analisi predittiva - 7 differenze utili
- Data Scientist vs Business Analyst - Scopri le 5 differenze impressionanti
- Data Scientist vs Data Engineer - 7 confronti sorprendenti
- Domande di intervista sull'ingegneria del software | Migliori e più richiesti