

Introduzione all'installazione Hive
In Hive Installation ci dovrebbero essere alcuni prerequisiti prima dell'installazione.
I componenti di Hadoop come Hive, Hbase, Pig, ecc. Supportano tutti l'ambiente Linux. Pertanto, si consiglia di disporre di un sistema operativo Linux sul dispositivo. In caso contrario, si desidera esercitarsi su hive pur avendo Windows sul proprio sistema. Quello che puoi fare è installare la macchina CDH sul tuo sistema e utilizzarla come piattaforma per esplorare Hadoop. Ciò richiederà un minimo di 4 GB di RAM sul sistema oppure è possibile disporre di una macchina CDH nella pen drive e utilizzarla.
Ad ogni modo puoi sempre avere una soluzione alla tua domanda che forse prima o poi.
Prerequisiti per installare Hive
Esistono alcuni prerequisiti per installare hive su qualsiasi macchina:
- Installazione Java
- Installazione di Hadoop
Passo 1
- Verifica che Java sia installato.
- Apri il Terminale e digita il comando.
Java-Version
- Se java è installato sul sistema ti darà la versione oppure un errore. Nel mio caso, Java è già installato e di seguito è riportato l'output del comando.

- Nel caso in cui Java non sia installato nel tuo sistema. Puoi visitare il link qui sotto e scaricare java e installarlo.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Installazione Java
- Estrai il download.
- Spostalo su "/ usr / local /".
- Imposta le variabili PATH e JAVA_HOME.
Passo 2
- Verifica che Hadoop sia installato.
- Apri il Terminale e digita il comando.
Hadoop-Version
- Se Hadoop è già installato, questo comando ti darà la versione oppure un errore.
- Nel mio caso, Hadoop ha già installato quindi l'output di seguito.
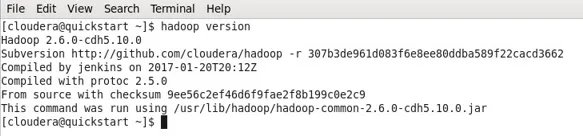
- Ora puoi osservare che sto lavorando con una macchina CDH5.
- Se Hadoop non è installato, scaricare Hadoop dalla base software Apache.
Installazione di Hadoop
1. Installa Hadoop
2. Configura Hadoop
I file che devono essere modificati per configurare Hadoop sono:
- core-site.xml
- HDFS-site.xml
- filati-site.xml
- mapred-site.xml
3. Configurare Namenode usando il comando:
Hdfs namenode -format
4. Avviare dfs usando il comando seguente:
start -dfs.sh
5. Avviare il filo usando il comando:
Start -yarn.sh
Come installare Hive?
Sotto i punti aiuta a installare hive:
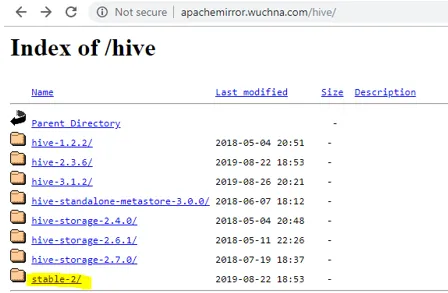
- La prima cosa che dobbiamo fare è scaricare la versione hive che può essere eseguita facendo clic sul collegamento seguente: http://apachemirror.wuchna.com/hive/
- Il link sopra ti darà il link da cui devi scegliere stable-2 evidenziato sotto in giallo:
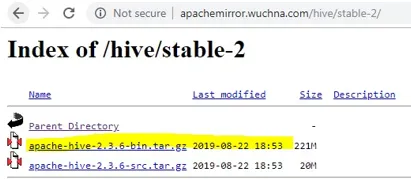
- Dopo aver aperto stable-2, scegli il file bin (evidenziato in giallo nella schermata) e fai clic con il tasto destro e "copia indirizzo link".
Passaggi per installare Hive
Di seguito sono i passaggi per installare hive:
Passaggio 1: scarica il file tar.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Passaggio 2: estrarre il file.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Passaggio 3: spostare i file apache nella directory / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Passaggio 4: configurare l'ambiente Hive aggiungendo le seguenti righe al file ~ / .bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Passaggio 5: eseguire il file bashrc.
$ source ~/.bashrc
Passaggio 6: Configurazione Hive : modifica il file hive-env.sh per aggiungere questo:
export HADOOP_HOME=/usr/local/Hadoop
Passaggio 7: modifica utilizzando i comandi seguenti:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Ora per verificare che l'hive sia installato o meno, usa il comando hive-version.
- Qui, la versione hive entra nella shell hive, il che significa che l'hive è installato. Tuttavia, nel mio caso, è la versione precedente che quindi dà l'avvertimento.

Conclusione - Installazione dell'alveare
Hive apre i big data a molte persone per la sua semplicità e natura simile a SQL come il linguaggio delle query e le interfacce. Hive è basato sul core Hadoop in quanto utilizza Mapreduce per l'esecuzione. Molto facile recuperare i dati ed eseguire l'elaborazione dei Big Data.
Articoli consigliati
Questa è una guida all'installazione di Hive. Qui discutiamo alcuni prerequisiti per installare hive su qualsiasi macchina e come installare hive in passaggi per una migliore comprensione. Puoi anche consultare i nostri altri articoli correlati per saperne di più-
- Che cos'è un alveare?
- Comandi alveare
- Come installare Hive
- Che cos'è il maiale?