

Introduzione all'hashing nel DBMS
Quando parliamo dell'enorme struttura del database e della loro complessità, diventa molto inefficiente cercare tutti gli indici e raggiungere i dati desiderati diventa molto vago e una possibilità complessa. Utilizzando la tecnica di hashing è possibile raggiungere questi stati e assegnare un puntatore diretto per conoscere l'esatta e la posizione diretta sul disco per il particolare record senza utilizzare la complessa struttura dell'indice. I dati in caso di tecnica di hashing vengono archiviati sotto forma di blocchi di dati il cui indirizzo viene generato facendo uso della funzione tipicamente nota come funzione di hashing. La posizione nella memoria in cui risiedono e sono archiviati i record è nota come blocchi di dati o bucket di dati.
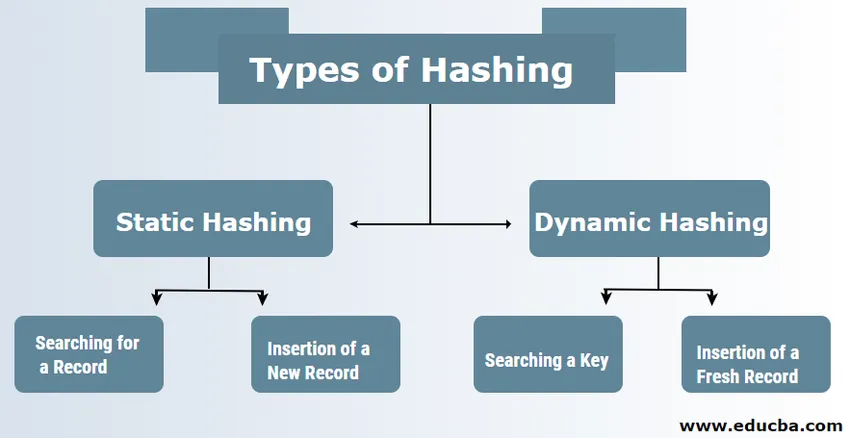
Tipi di hash nel DBMS
Esistono in genere due tipi di tecniche di hash nel DBMS:
1. Hashing statico
2. Hashing dinamico
1) Hashing statico
Nel caso di hash statico, il set di dati formato e l'indirizzo bucket sono gli stessi. Ciò significa che se proviamo a generare l'indirizzo per USER_ID = 113 utilizzando il modulo di funzione di hashing 5, ci fornisce sempre il risultante 3 con lo stesso indirizzo bucket. In questo caso, non ci saranno cambiamenti nell'indirizzo del bucket fornito. Pertanto il numero di secchi rimane costante durante l'operazione.
Operazione di hash tipicamente statico
un. Ricerca di un record: se è necessario trovare il record, viene utilizzata la stessa identica funzione di hashing per recuperare l'indirizzo e il percorso del bucket dati con i dati archiviati.
b. Inserimento di un nuovo record: se un record nuovo e aggiornato viene inserito in una tabella, viene generato un indirizzo per un nuovo record basato sulla chiave di hashing, memorizzando così il record in quella posizione.
- Eliminazione del record: per poter eliminare il record, è necessario prima recuperare quel record che può essere eliminato. Al termine di tale attività, è necessario eliminare i record per quell'indirizzo di memoria.
- Aggiornamento di un record: al fine di aggiornare il record, cerchiamo innanzitutto nel record facendo uso della funzione basata su hash e, una volta fatto, il nostro record di dati può essere considerato in uno stato aggiornato. Per consentirci di inserire un nuovo record nel file e l'indirizzo generato dalla funzione basata su hash e dal bucket dei dati non è vuoto o se i dati sono già presenti nell'indirizzo fornito. Questa situazione che si presenta in particolare in caso di hash statico può essere meglio chiamata overflow della benna e quindi ci sono alcuni modi usati per superare questo problema come:
(i) Open Hashing: se una funzione di hashing genera l'indirizzo per il quale i dati possono essere visti già nello stato memorizzato, in quel caso, il livello successivo del bucket verrà assegnato automaticamente. Questo meccanismo può essere definito come una tecnica di sondaggio lineare.
Ad esempio, se R3 è l'indirizzo nuovo che è necessario inserire, la funzione basata su hash genererà l'indirizzo come numero 102 per l'indirizzo R3. L'indirizzo generato è in pieno stato e quindi il sistema è pensato per cercare il nuovo bucket di dati che è 113 e assegnare R3 a quel bucket di dati.
(ii) Hashing chiuso: quando i bucket sono completamente pieni, viene assegnato un nuovo bucket per un particolare risultato hash che viene collegato subito dopo quello completato in precedenza e pertanto questo metodo viene chiamato come tecnica di concatenamento di overflow.
Ad esempio, R3 è l'indirizzo nuovo che deve essere inserito nella nuova tabella con la funzione di hashing per generare l'indirizzo come numero 110. Questo bucket, a sua volta, è pieno e quindi non può ricevere nuovi dati e quindi un bucket nuovo viene inserito alla fine dopo 100.
2) Hashing dinamico
Questo tipo di metodo basato su hash può essere utilizzato per risolvere i problemi di base dell'hash basato su statici come quelli come l'overflow dei bucket poiché i bucket di dati possono crescere e ridursi con la dimensione che è una tecnica più ottimizzata per lo spazio e quindi viene chiamata Estensibile metodo basato su hash. In questo metodo, l'hash viene reso dinamico, il che significa che l'attività di inserimento o cancellazione è consentita senza andare a fornire prestazioni scadenti.
un. Ricerca di una chiave: calcola l'indirizzo basato su hash della chiave richiesta e controlla il numero di bit che vengono utilizzati nel caso di una directory nota come i. Quindi quelli che sono meno significativi dei bit I sono presi dalla directory che dà un'idea dell'indice dalla directory. Usando quel valore di indice, vai nella directory per trovare l'indirizzo bucket per cercare i record attuali.
b. Inserimento di un nuovo record: all'inizio, è necessario seguire esattamente la stessa procedura di recupero che deve finire da qualche parte nel secchio. Cerca lo spazio in quel bucket, quindi inserisci i record al suo interno. Se quel bucket creato è completo e pieno, il bucket verrà suddiviso e i record verranno ridistribuiti.
Ad esempio, gli ultimi due bit delle cifre 2 e 4 sono 00. Quindi andranno nel bucket B0 e così via in base alla funzione del modulo. La chiave 9 ha un indirizzo di 10001 che deve essere presente nel primo bucket ma verrà suddiviso e si sposterà nel nuovo bucket B1 e continuerà fino a quando tutti i bucket e le chiavi non saranno dinamicamente cancellati. La funzione hash viene utilizzata in un modo in cui la funzione hash viene utilizzata per scegliere la colonna e il suo valore per generare l'indirizzo. Numero massimo di volte in cui la funzione hash utilizza la chiave primaria che a sua volta viene utilizzata per generare gli indirizzi del blocco dati. È una semplice funzione matematica in cui la chiave primaria può anche essere considerata come l'indirizzo del blocco dati, il che significa che ogni riga con lo stesso indirizzo di quella della chiave primaria verrà memorizzata nel blocco dati.
Articoli consigliati
Questa è una guida all'hashing nel DBMS. Qui discutiamo dell'introduzione e dei diversi tipi di hash nel DBMS che include un hash statico e un hash dinamico insieme ad esempi. Puoi anche dare un'occhiata ai seguenti articoli per saperne di più -
- Modelli di dati in DBMS
- Vantaggi del DBMS
- Strumento di integrazione dei dati
- Che cos'è RDBMS?