

Cos'è la funzione Hive?
Come sappiamo oggi Hadoop è una delle tecnologie versatili nei big data. Hadoop ha la capacità di far fronte a un set di dati di grandi dimensioni, ma poiché la crescita dei dati è proporzionale, scrivere programmi di riduzione delle mappe diventa difficile. Per eseguire query SQL, presente in HDFS una tale tecnologia è stata introdotta da Hadoop chiamata apache Hive avviata da Facebook. Hive è molto utilizzato dall'analista di dati. Sono distribuiti per tre funzionalità: riepilogo dei dati, analisi dei dati su file distribuito e query di dati. Hive fornisce query simili a SQL chiamate HQL: un linguaggio di query elevato supporta DML, funzioni definite dall'utente. Il compilatore Hive converte internamente questa query in lavori di riduzione della mappa che semplificano il lavoro di Hadoop nella scrittura di programmi complessi. Potremmo trovare un alveare in applicazioni come Data warehousing, visualizzazione dei dati e analisi ad hoc, google analytics. Il vantaggio principale è che fanno uso della conoscenza di SQL, che è un'abilità di base implementata tra data scientist e professionisti del software.
Diverse funzioni dell'alveare in dettaglio
Hive supporta diversi tipi di dati che non si trovano in altri sistemi di database. include una mappa, un array e una struttura. Hive ha alcune funzioni integrate per eseguire diverse funzioni matematiche e aritmetiche per uno scopo speciale. Le funzioni in hive possono essere classificate nei seguenti tipi. Sono funzioni integrate e funzioni definite dall'utente.
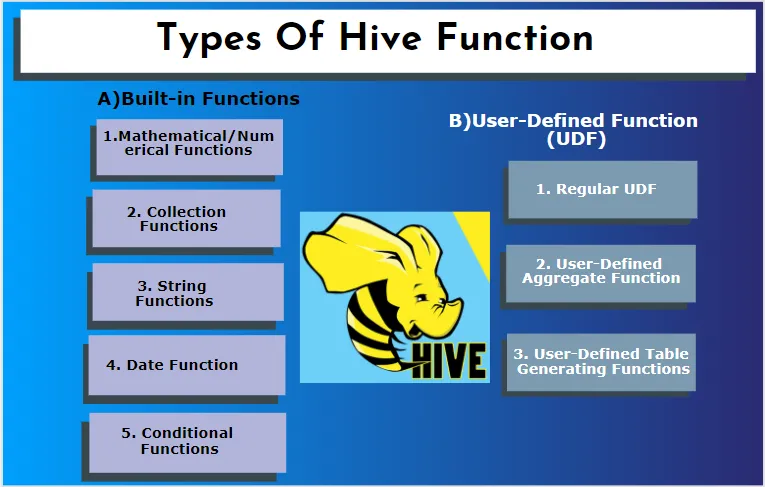
A) Funzioni integrate
Queste funzioni estraggono i dati dalle tabelle degli alveari ed elaborano i calcoli. Alcune delle funzioni integrate sono:
1. Funzioni matematiche / numeriche
Queste funzioni sono utilizzate principalmente per calcoli matematici. Queste funzioni sono utilizzate nelle query SQL.
| Nome funzione | Esempio | Descrizione |
| ABS (doppio x) | Hive> seleziona ABS (-200) da tmp; | Restituirà il valore assoluto di un numero. |
| CEIL (doppia x) | Hive> seleziona CEIL (8.5) da tmp; | Recupera il numero intero più piccolo maggiore o uguale al valore x. |
| Rand (), rand (int seed) | Hive> seleziona Rand () da tmp;
Rand (0-9) | Restituisce un numero casuale, dipende dal valore del seme che i numeri casuali generati sarebbero deterministici. |
| Pow (doppio x, doppio y) | Hive> seleziona Pow (5, 2) da tmp; | Restituisce il valore x elevato alla potenza y. |
| PIANO (doppio y) | Hive> seleziona FLOOR (11.8) da tmp; | Restituisce un numero intero massimo inferiore o uguale a dare valore y. |
| SCAD (doppia a) | Hive> seleziona Exp (30) da tmp; | Restituirà il valore esponente di 30. i valori dell'algoritmo naturale. |
| PMOD (int a, int b) | Hive> seleziona PMOD (2, 4) da tmp; | Dà il modulo positivo del numero. |
2. Funzioni di raccolta
Il dump di tutti gli elementi insieme e la restituzione di singoli elementi dipende dal tipo di dati incluso.
| Nome della funzione | Esempio | Descrizione |
| Map_values (Mappa) | Hive> seleziona valori mappa ('hi', 45) | Recupera gli elementi dell'array non ordinati. |
| Dimensione (Mappa) | Alveare> seleziona dimensione (mappa) | Restituisce il numero di elementi nella mappa del tipo di dati. |
| Array_contains (Array b) | Hive> select array_contains (a (10)) | Restituisce VERO se l'array contiene il valore. |
| Sort_array (Array a) | Hive> select sort_array ((10, 3, 6, 1, 7)) | Ordina l'array di input in ordine crescente in base all'ordinamento naturale degli elementi dell'array e restituisce il valore. |
3. Funzioni stringa
Utilizzando le funzioni stringa l'analisi dei dati viene eseguita in modo eccellente.
| Split (stringa s, stringa pat) | Hive> seleziona output diviso ('educba ~ hive ~ Hadoop, ' ~ '): ("educba", "hive", "Hadoop") | Divide la stringa attorno alle espressioni pat e restituisce un array. |
| load (string s, int Len, pad string) | Hive> seleziona carico ('EDUCBA', 6, 'H') | Restituisce le stringhe con un'imbottitura destra con la lunghezza della stringa. (carattere pad). |
| Lunghezza (stringa str) | Hive> seleziona lunghezza ('educba') | Questa funzione restituisce la lunghezza della stringa. |
| Rtrim (stringa a) | Hive> select rtrim ('TOPIC');
Output: 'Argomento' | Restituisce il risultato tagliando gli spazi dalle estremità giuste. |
| Concat (stringa m, stringa n) | Hive> select concat ('data', 'ware') Risultato: Dataware | Risulta nella stringa eseguendo la concatenazione di due stringhe, ciò può richiedere qualsiasi numero di input. |
| Inverso (stringa) | Hive> seleziona reverse ('Mobile') | Restituisce il risultato di una stringa invertita. |
4. Funzione data
È necessario disporre del formato dati nell'hive per evitare errori Null nell'output. È necessario disporre della compatibilità con la data per utilizzare le funzioni di data introdotte in hive.
| Unix_timestamp (Data stringa, modello stringa) | Hive> seleziona Unix_ timestamp ('2019-06-08', 'yyyy-mm-dd'); Risultato: 124576 400 tempo impiegato: 0, 146 secondi | Questa funzione restituisce la data al formato specifico e restituisce i secondi tra la data e l'ora Unix. |
| Unix_timestamp (data stringa) | Hive> seleziona Unix_ timestamp ('2019-06-08 09:20:10', 'yyyy-mm-dd'); | Restituisce la data nel formato 'aaaa-MM-gg HH: mm: ss' nel timestamp Unix. |
| Ora (data stringa) | Alveare> seleziona ora ('2019-06-08 09:20:10'); Risultato: 09 ore | Restituisce l'ora del timestamp |
5. Funzioni condizionali
| If (test booleano, valore T vero, t falso) | Hive> seleziona IF (1 = 1, 'TRUE', 'FALSE') come IF_CONDITION_TEST; | Verifica con la condizione se il valore è true restituisce 1 e false restituisce 0. |
| Non è null (b) | Hive> Select non è null (null); | Questo recupera non le dichiarazioni null. se null restituisce false. |
| Coalesce (valore1, valore2) | Esempio: hive> select coalesce (Null, null, 4, null, 6). restituisce 4. | Recupera prima i valori non nulli dall'elenco di valori. |
B) Funzione definita dall'utente (UDF)
Hive utilizza funzioni specifiche dell'utente in base alle esigenze del client scritte nella programmazione Java. È implementato da due interfacce ovvero API semplici e API complesse. Vengono richiamati dalla query hive. Tre tipi di UDF:
1. UDF regolare
Funziona su un tavolo con una sola riga. Viene creato creando una classe java, quindi impacchettandoli in un file .jar, il passo successivo è verificare con un percorso di classe hive. poi infine eseguirli in una query hive.
2. Funzione aggregata definita dall'utente
Usano funzioni aggregate come avg / mean implementando cinque metodi init (), iterate (), partial (), merge (), terminate ().
3. Funzioni di generazione della tabella definite dall'utente
Funziona con una singola riga in una tabella e risulta in più righe.
Conclusione
In conclusione, abbiamo imparato in dettaglio come lavorare nella piattaforma hive con funzioni integrate e funzioni definite dall'utente in dettaglio attraverso questo articolo. La maggior parte delle organizzazioni ha programmatore e sviluppatore SQL per lavorare sul processo lato server, ma un alveare di apache è un potente strumento che li aiuta a utilizzare il framework Hadoop senza alcuna conoscenza precedente dei programmi e della riduzione delle mappe. Hive aiuta i nuovi utenti ad avviare ed esplorare l'analisi dei dati senza barriere.
Articoli consigliati
Questa è una guida alla funzione alveare. Qui discutiamo il concetto, due diversi tipi di funzioni e sotto-funzioni in Hive. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Principali funzioni di stringa in Hive
- Interviste sull'alveare
- Che cos'è Oracle RMAN?
- Cos'è il modello Waterfall?
- Introduzione all'architettura alveare
- Hive Order di