

Che cos'è l'algoritmo Naive Bayes?
Naive Bayes Algorithm è una tecnica che aiuta a costruire classificatori. I classificatori sono i modelli che classificano le istanze del problema e forniscono loro etichette di classe che sono rappresentate come vettori di predittori o valori di funzionalità. Si basa sul teorema di Bayes. Si chiama Bayes ingenuo perché presuppone che il valore di una funzione sia indipendente dall'altra caratteristica, ovvero la modifica del valore di una caratteristica non influirebbe sul valore dell'altra caratteristica. È anche chiamato idiota Bayes per lo stesso motivo. Questo algoritmo funziona in modo efficiente per set di dati di grandi dimensioni, quindi più adatto per le previsioni in tempo reale.
Aiuta a calcolare la probabilità posteriore P (c | x) utilizzando la probabilità precedente della classe P (c), la probabilità precedente del predittore P (x) e la probabilità del predittore data classe, chiamata anche come probabilità P (x | c ).
La formula o l'equazione per calcolare la probabilità posteriore è:
- P (c | x) = (P (x | c) * P (c)) / P (x)
Come funziona Naive Bayes Algorithm?
Cerchiamo di capire il funzionamento di Naive Bayes Algorithm usando un esempio. Assumiamo un set di dati di allenamento del tempo e la variabile target "Fare shopping". Ora classificheremo se una ragazza andrà a fare shopping in base alle condizioni meteorologiche.
Il set di dati indicato è:
| Tempo metereologico | Fare shopping |
| soleggiato | No |
| Piovoso | sì |
| nuvoloso | sì |
| soleggiato | sì |
| nuvoloso | sì |
| Piovoso | No |
| soleggiato | sì |
| soleggiato | sì |
| Piovoso | No |
| Piovoso | sì |
| nuvoloso | sì |
| Piovoso | No |
| nuvoloso | sì |
| soleggiato | No |
Verranno eseguiti i seguenti passaggi:
Passaggio 1: Creare tabelle di frequenza utilizzando set di dati.
| Tempo metereologico | sì | No |
| soleggiato | 3 | 2 |
| nuvoloso | 4 | 0 |
| Piovoso | 2 | 3 |
| Totale | 9 | 5 |
Passaggio 2: crea una tabella delle probabilità calcolando le probabilità di ciascuna condizione meteorologica e andando a fare shopping.
| Tempo metereologico | sì | No | Probabilità |
| soleggiato | 3 | 2 | 5/14 = 0, 36 |
| nuvoloso | 4 | 0 | 4/14 = 0, 29 |
| Piovoso | 2 | 3 | 5/14 = 0, 36 |
| Totale | 9 | 5 | |
| Probabilità | 9/14 = 0, 64 | 5/14 = 0, 36 |
Step 3: Ora dobbiamo calcolare la probabilità posteriore usando l'equazione di Naive Bayes per ogni classe.
Esempio di problema: una ragazza andrà a fare shopping se il tempo è nuvoloso. Questa affermazione è corretta?
Soluzione:
- P (Sì | Coperto) = (P (Coperto | Sì) * P (Sì)) / P (Coperto)
- P (Coperto | Sì) = 4/9 = 0.44
- P (Sì) = 9/14 = 0.64
- P (coperto) = 4/14 = 0, 39
Ora inserisci tutti i valori calcolati nella formula sopra
- P (Sì | Coperto) = (0.44 * 0.64) / 0.39
- P (Sì | Coperto) = 0.722
La classe con la massima probabilità sarebbe il risultato della previsione. Utilizzando lo stesso approccio è possibile prevedere le probabilità di classi diverse.
A cosa serve l'algoritmo Naive Bayes?
1. Previsione in tempo reale: l' algoritmo Naive Bayes è veloce e sempre pronto per l'apprendimento, quindi più adatto alle previsioni in tempo reale.
2. Previsione multi-classe: la probabilità di multi-classi di qualsiasi variabile target può essere prevista usando un algoritmo Naive Bayes.
3. Sistema di raccomandazioni: il classificatore Naive Bayes con l'aiuto del filtro collaborativo crea un sistema di raccomandazioni. Questo sistema utilizza tecniche di data mining e machine learning per filtrare le informazioni che non sono state viste in precedenza e quindi prevedere se un utente apprezzerebbe o meno una determinata risorsa.
4. Classificazione del testo / Analisi del sentimento / Filtro antispam: grazie alle sue migliori prestazioni con problemi multi-classe e alla sua regola di indipendenza, l'algoritmo Naive Bayes ha prestazioni migliori o ha un tasso di successo più elevato nella classificazione del testo, pertanto viene utilizzato in Analisi del sentimento e Filtro antispam.
Vantaggi dell'algoritmo Naive Bayes
- Facile da implementare.
- Veloce
- Se il presupposto di indipendenza è valido, funziona in modo più efficiente rispetto ad altri algoritmi.
- Richiede meno dati di allenamento.
- È altamente scalabile.
- Può fare previsioni probabilistiche.
- Può gestire sia dati continui che discreti.
- Insensibile alle caratteristiche irrilevanti.
- Può funzionare facilmente con valori mancanti.
- Facile da aggiornare all'arrivo di nuovi dati.
- Adatto per problemi di classificazione del testo.
Svantaggi dell'algoritmo Naive Bayes
- Il forte presupposto che le funzionalità siano indipendenti è quasi impossibile nelle applicazioni della vita reale.
- Scarsità di dati.
- Possibilità di perdita di precisione.
- Frequenza zero, ovvero se la categoria di qualsiasi variabile categoriale non viene visualizzata nel set di dati di allenamento, il modello assegna una probabilità zero a quella categoria e quindi non è possibile effettuare una previsione.
Come costruire un modello base usando Naive Bayes Algorithm
Esistono tre tipi di modelli Naive Bayes, ovvero gaussiano, multinomiale e bernoulli. Discutiamo brevemente ciascuno di essi.
1. Gaussiano: l' algoritmo gaussiano di Bayes Naive presuppone che i valori continui corrispondenti a ciascuna caratteristica siano distribuiti secondo la distribuzione gaussiana chiamata anche distribuzione normale.
Si presume che la probabilità o la probabilità precedente del predittore di una determinata classe sia gaussiana, pertanto la probabilità condizionata può essere calcolata come:
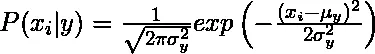
2. Multinomiale: le frequenze del verificarsi di determinati eventi rappresentate da vettori di caratteristiche vengono generate utilizzando la distribuzione multinomiale. Questo modello è ampiamente utilizzato per la classificazione dei documenti.
3. Bernoulli: in questo modello, gli input sono descritti dalle caratteristiche che sono variabili binarie indipendenti o booleane. Questo è anche ampiamente usato nella classificazione dei documenti come Multinomial Naive Bayes.
È possibile utilizzare uno dei modelli di cui sopra in base alle esigenze per gestire e classificare il set di dati.
Puoi costruire un modello gaussiano usando Python comprendendo l'esempio riportato di seguito:
Codice:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
Produzione:
((3, 4))
Conclusione
In questo articolo, abbiamo imparato i concetti di Naive Bayes Algorithm in dettaglio. È utilizzato principalmente nella classificazione del testo. È facile da implementare e veloce da eseguire. Il suo principale svantaggio è che richiede che le funzionalità siano indipendenti, il che non è vero nelle applicazioni della vita reale.
Articoli consigliati
Questa è stata una guida per Naive Bayes Algorithm. Qui abbiamo discusso il concetto di base, il funzionamento, i vantaggi e gli svantaggi dell'algoritmo Naive Bayes. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Promuovere l'algoritmo
- Algoritmo in programmazione
- Introduzione all'algoritmo