

Introduzione a Python Pandas DataFrame
Espansioni multiple per la libreria Python, Panda, sono disponibili online. Uno di questi è Panel (pan) Data (das). Questa parola, * Panel *, suggerisce in modo sottile una struttura di dati bidimensionale presente in questa libreria, potenziando immensamente i suoi utenti. Questa stessa struttura si chiama DataFrame.
È essenzialmente una matrice di righe e colonne, contenente l'intero set di dati, con opzioni molto elaborate di indicizzazione dello stesso. Il DataFrame (DF) può essere immaginato pittoricamente molto simile a un foglio Excel. Ma ciò che lo rende potente è la facilità con cui le operazioni analitiche e di trasformazione possono essere eseguite sui dati memorizzati in un DataFrame.
Cos'è esattamente un DataFrame di Python Pandas?
La pagina di Pydata può essere riferita per qualcosa di una definizione ufficiale.
Se compreso correttamente, menziona DataFrame come una struttura colonnare, in grado di memorizzare qualsiasi oggetto Python (incluso un DataFrame stesso) come un valore di cella. (Una cella viene indicizzata utilizzando una combinazione unica di riga e colonna)
DataFrames è costituito da tre componenti essenziali: dati, righe e colonne.
- Dati: si riferisce agli oggetti / entità reali memorizzati in una cella nel DataFrame e ai valori rappresentati da queste entità. Un oggetto è di qualsiasi tipo di dati Python valido, integrato o definito dall'utente.
- Righe: i riferimenti utilizzati per identificare (o indicizzare) una particolare serie di osservazioni dai dati completi memorizzati in un DataFrame vengono chiamati come Righe. Giusto per chiarire, rappresenta gli indici utilizzati e non solo i dati in una particolare osservazione.
- Colonne: riferimenti utilizzati per identificare (o indicizzare) un set di attributi per tutte le osservazioni in un DataFrame. Come nel caso delle righe, si riferiscono all'indice di colonna (o alle intestazioni di colonna) anziché solo ai dati nella colonna.
Quindi, senza ulteriori indugi, proviamo alcuni modi per creare queste strutture incredibilmente potenti.
Passaggi per la creazione di DataFrame di Python Pandas
Un DataFrame di Python Pandas può essere creato utilizzando la seguente implementazione di codice,
1. Importare i panda
Per creare DataFrames, la libreria panda deve essere importata (nessuna sorpresa qui). Lo importeremo con un pd alias per fare riferimento a oggetti nel modulo comodamente.
Codice:
import pandas as pd
2. Creazione del primo oggetto DataFrame
Una volta importata la libreria, tutti i metodi, le funzioni e i costruttori sono disponibili nell'area di lavoro. Quindi, proviamo a creare un DataFrame alla vaniglia.
Codice:
import pandas as pd
df = pd.DataFrame()
print(df)
Produzione:
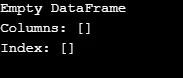
Come mostrato nell'output, il costruttore restituisce un DataFrame vuoto.
Concentriamoci ora sulla creazione di DataFrame dai dati memorizzati in alcune delle rappresentazioni probabili.
- DataFrame da un dizionario: supponiamo di avere un dizionario in cui è memorizzato un elenco di società in Software Domain e il numero di anni in cui sono state attive.
Codice:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Vediamo la rappresentazione dell'oggetto DataFrame restituito stampandolo sulla console.
Produzione:

Come si può vedere, ogni chiave del dizionario viene trattata come una colonna nel DataFrame e gli indici di riga vengono generati automaticamente a partire da 0. Abbastanza facile eh!
Ora diciamo che volevi dargli un indice personalizzato invece di 0, 1, .. 4. Devi solo passare la lista desiderata come parametro al costruttore e i panda faranno il necessario.
Codice:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Produzione:
Età dell'azienda
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Ora puoi impostare gli indici di riga su qualsiasi valore desiderato.
- DataFrame da un file CSV: creiamo un file CSV contenente gli stessi dati del caso del nostro dizionario. Chiamiamo il file CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Diretti, 22
Il file può essere caricato in un dataframe (supponendo che sia presente nella directory di lavoro corrente) come segue.
Codice:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Produzione:
Età dell'azienda
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
L'impostazione dei nomi dei parametri , ignorando un elenco di valori, li assegna come intestazioni di colonna nello stesso ordine in cui sono presenti nell'elenco. Allo stesso modo, gli indici di riga possono essere impostati passando un elenco al parametro index, come mostrato nella sezione precedente. L'intestazione = None indica le intestazioni di colonna mancanti nel file di dati.
Supponiamo ora che i nomi delle colonne facessero parte del file di dati. Quindi l'impostazione header = False farà il lavoro richiesto.
3. CompanyAgeWithHeader.csv
Azienda, Età
Google, 21
Amazon, 23
Infosys, 38
Diretti, 22
Il codice cambierà in
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Produzione:
Età dell'azienda
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame da un file Excel: spesso i dati sono condivisi in file Excel in quanto rimane lo strumento più popolare utilizzato dalla gente comune per il monitoraggio Adhoc. Pertanto, non dovrebbe essere ignorato dalla nostra discussione.
Supponiamo che i dati, come in CompanyAgeWithHeader.csv, siano ora archiviati in CompanyAgeWithHeader.xlsx, in un foglio con il nome di Company Age. Lo stesso DataFrame di cui sopra verrà creato dal seguente codice.
Codice:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Produzione:
Età dell'azienda
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Come puoi vedere, lo stesso DataFrame può essere creato passando il nome del file e il nome del foglio.
Ulteriori letture e passaggi successivi
I metodi mostrati costituiscono un sottoinsieme molto piccolo rispetto a tutti i diversi modi in cui DataFrames può essere creato. Questi sono stati creati con l'intenzione di avviarne uno. Dovresti assolutamente esplorare i riferimenti elencati e provare ad esplorare altri modi, inclusa la connessione a un database per leggere i dati direttamente in un DataFrame.
Conclusione
Pandas DataFrame ha dimostrato di essere un punto di svolta nel mondo della scienza dei dati e dell'analisi dei dati, nonché conveniente per i progetti ad hoc a breve termine. Viene fornito con un esercito di strumenti in grado di tagliare e tagliare il set di dati con estrema facilità. Spero che questo serva da trampolino di lancio nel tuo viaggio.
Articoli consigliati
Questa è una guida a Python-Pandas DataFrame. Qui discutiamo i passaggi per la creazione di dataframe python-panda insieme alla sua implementazione del codice. Puoi anche consultare i seguenti articoli per saperne di più -
- Le 15 principali caratteristiche di Python
- Diversi tipi di set di Python
- I 4 migliori tipi di variabili in Python
- I 6 migliori redattori di Python
- Matrici nella struttura dei dati