
Introduzione a Bagging and Boosting
Bagging e Boosting sono i due metodi Ensemble più popolari. Quindi, prima di capire Bagging and Boosting, abbiamo un'idea di cosa sia l'ensemble Learning. È la tecnica per utilizzare più algoritmi di apprendimento per formare modelli con lo stesso set di dati per ottenere una previsione nell'apprendimento automatico. Dopo aver ottenuto la previsione da ciascun modello, utilizzeremo tecniche di media dei modelli come media ponderata, varianza o voto massimo per ottenere la previsione finale. Questo metodo mira a ottenere previsioni migliori rispetto al singolo modello. Ciò si traduce in una migliore accuratezza evitando un eccesso di adattamento e riduce distorsioni e co-varianza. Due metodi di ensemble popolari sono:
- Insaccamento (Bootstrap Aggregating)
- Aumentare
insacco:
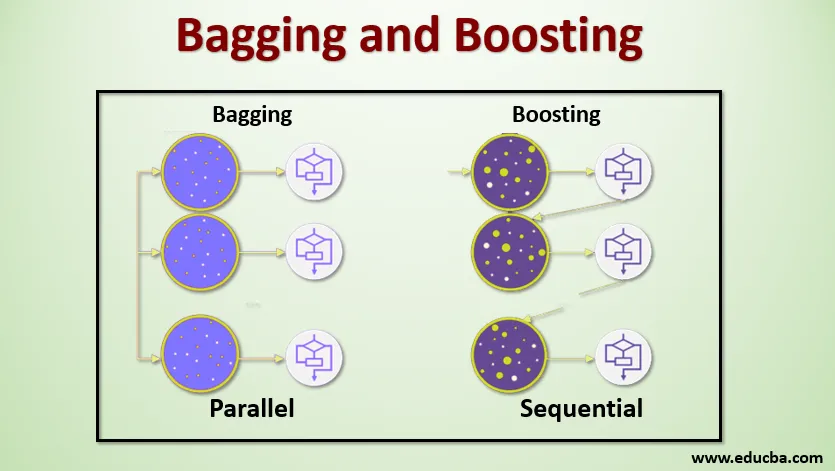
Il bagging, noto anche come Bootstrap Aggregating, viene utilizzato per migliorare l'accuratezza e rendere il modello più generalizzato riducendo la varianza, ovvero evitando un eccesso di adattamento. In questo, prendiamo più sottoinsiemi del set di dati di addestramento. Per ogni sottoinsieme, prendiamo un modello con gli stessi algoritmi di apprendimento come l'albero decisionale, la regressione logistica, ecc. Per prevedere l'output per lo stesso set di dati di test. Una volta che abbiamo una previsione da ciascun modello, utilizziamo una tecnica di media del modello per ottenere l'output della previsione finale. Una delle famose tecniche utilizzate in Bagging è Random Forest . Nella foresta casuale, utilizziamo più alberi decisionali.
Potenziamento :
Il potenziamento viene utilizzato principalmente per ridurre la tendenza e la varianza in una tecnica di apprendimento supervisionato. Si riferisce alla famiglia di un algoritmo che converte i discenti deboli (studente di base) in discenti forti. Lo studente debole è i classificatori che sono corretti solo in piccola parte con la classificazione effettiva, mentre gli studenti forti sono i classificatori che sono ben correlati con la classificazione effettiva. Poche famose tecniche di Boosting sono AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Quindi ora sappiamo cosa sono il bagging e il potenziamento e quali sono i loro ruoli in Machine Learning.
Funzionamento di insaccamento e potenziamento
Ora capiamo come funzionano il bagging e il potenziamento:
insacco
Per comprendere il funzionamento di Bagging, supponiamo di avere un numero N di modelli e un set di dati D. Dove m è il numero di dati e n è il numero di funzionalità in ciascun dato. E dovremmo fare una classificazione binaria. Innanzitutto, divideremo il set di dati. Per ora, suddivideremo questo set di dati solo in training e set di test. Chiamiamo il set di dati di training come dov'è il numero totale di esempi di training.
Prendi un campione di record dal set di addestramento e usalo per allenare il primo modello, ad esempio m1. Per il modello successivo, m2 ricampiona il set di allenamento e preleva un altro campione dal set di allenamento. Faremo la stessa cosa per il numero N di modelli. Poiché stiamo ricampionando il set di dati di training e prelevando i campioni da esso senza rimuovere nulla dal set di dati, potrebbe essere possibile avere due o più record di dati di training comuni in più campioni. Questa tecnica di ricampionamento del set di dati di addestramento e di fornitura del campione al modello è definita campionamento di righe con sostituzione. Supponiamo di aver addestrato ogni modello e ora vogliamo vedere la previsione sui dati dei test. Poiché stiamo lavorando sull'output della classificazione binaria può essere 0 o 1. Il set di dati di test viene passato a ciascun modello e otteniamo una previsione da ciascun modello. Diciamo che su N modelli più di N / 2 modelli hanno previsto che fosse 1, quindi Usando la tecnica della media del modello come voto massimo, possiamo dire che l'output previsto per i dati di test è 1.
Aumentare
Nel potenziamento prendiamo i record dal set di dati e li passiamo alle basi degli studenti in sequenza, qui gli studenti di base possono essere qualsiasi modello. Supponiamo di avere m numero di record nel set di dati. Quindi passiamo alcuni record per basare lo studente BL1 e addestrarlo. Una volta che BL1 viene addestrato, passiamo tutti i record dal set di dati e vediamo come funziona lo studente Base. Per tutti i record che sono classificati in modo errato dallo studente di base, li prendiamo e li passiamo ad altri studenti di base come BL2 e contemporaneamente passiamo i record errati classificati da BL2 per addestrare BL3. Ciò continuerà a meno che e fino a quando non specificheremo un numero specifico di modelli di studenti di base di cui abbiamo bisogno. Infine, uniamo l'output di questi apprendenti di base e creiamo uno studente forte, di conseguenza, il potere di predizione del modello viene migliorato. Ok. Quindi ora sappiamo come funzionano Bagging and Boosting.
Vantaggi e svantaggi di insaccamento e potenziamento
Di seguito sono riportati i principali vantaggi e svantaggi.
Vantaggi del confezionamento
- Il più grande vantaggio del bagging è che più studenti deboli possono lavorare meglio di un singolo studente forte.
- Fornisce stabilità e aumenta la precisione dell'algoritmo di apprendimento automatico utilizzato nella classificazione statistica e nella regressione.
- Aiuta a ridurre la varianza, cioè evita un eccesso di adattamento.
Svantaggi del insaccamento
- Può comportare un'inclinazione elevata se non è modellato correttamente e quindi può comportare un insufficiente adattamento.
- Dal momento che dobbiamo usare più modelli, diventa computazionalmente costoso e potrebbe non essere adatto in vari casi d'uso.
Vantaggi del potenziamento
- È una delle tecniche di maggior successo nel risolvere i problemi di classificazione di due classi.
- È bravo a gestire i dati mancanti.
Svantaggi di Boosting
- Il potenziamento è difficile da implementare in tempo reale a causa della maggiore complessità dell'algoritmo.
- L'elevata flessibilità di queste tecniche comporta un numero multiplo di parametri che hanno un effetto diretto sul comportamento del modello.
Conclusione
L'asporto principale è che Bagging e Boosting sono un paradigma di apprendimento automatico in cui utilizziamo più modelli per risolvere lo stesso problema e ottenere prestazioni migliori E se combiniamo correttamente gli studenti deboli, possiamo ottenere un modello stabile, preciso e robusto. In questo articolo, ho fornito una panoramica di base su Bagging e Boosting. Nei prossimi articoli imparerai le diverse tecniche utilizzate in entrambi. Infine, concluderò ricordandoti che il Bagging e il Boosting sono tra le tecniche più utilizzate di apprendimento dell'ensemble. La vera arte del miglioramento delle prestazioni risiede nella comprensione di quando utilizzare quale modello e come ottimizzare gli iperparametri.
Articoli consigliati
Questa è una guida a Bagging and Boosting. Qui discutiamo l'introduzione al bagging e il boosting e sta lavorando insieme a vantaggi e svantaggi. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Introduzione alle tecniche di ensemble
- Categorie di algoritmi di apprendimento automatico
- Algoritmo di potenziamento del gradiente con codice di esempio
- Cos'è l'algoritmo Boosting?
- Come creare l'albero decisionale?