
Introduzione all'architettura alveare
Hive Architecture è costruita sull'ecosistema Hadoop. L'alveare ha spesso interazioni con l'Hadoop. Apache Hive è in grado di gestire sia il sistema di database SQL del dominio sia Map-ridurre. Le applicazioni Hive possono essere scritte in varie lingue come Java, Python. L'architettura hive mostra come scrivere il linguaggio Query hive e come vengono fatte le interazioni tra il programmatore usando l'interfaccia della riga di comando. Il linguaggio delle query Hive ha il compito di convertire tutte le attività del cluster Hadoop tramite map-reduce. Come tutti sapevamo, Hadoop elabora i big data in un ambiente distribuito e forma un framework open source. Con hive, è flessibile gestire ed eseguire la query e un buon sostenitore per eseguire funzioni come incapsulamento, query ad hoc. Questo articolo fornisce una breve introduzione all'architettura hive che risiede sul livello Hadoop per eseguire il riepilogo in big data.
Hive Architecture con i suoi componenti
Hive svolge un ruolo importante nell'analisi dei dati e nell'integrazione di business intelligence e supporta formati di file come file di testo, file rc. Hive utilizza un sistema distribuito per elaborare ed eseguire query e l'archiviazione viene infine eseguita sul disco e infine elaborata utilizzando un framework di riduzione delle mappe. Risolve il problema di ottimizzazione riscontrato in map-riduc e hive esegue lavori batch che sono chiaramente spiegati nel flusso di lavoro. Qui un meta store memorizza le informazioni sullo schema. Un framework chiamato Apache Tez è progettato per l'esecuzione di query in tempo reale.
I componenti principali dell'Alveare sono riportati di seguito:
- Clienti alveari
- Servizi alveari
- Hive storage (Meta storage)
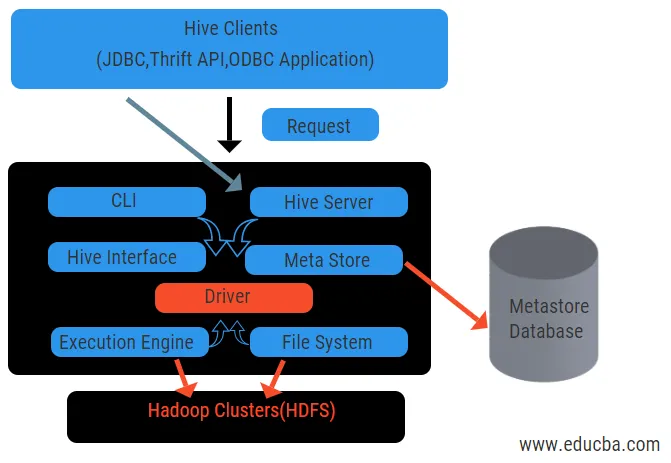
Il diagramma sopra mostra l'architettura dell'Alveare e i suoi elementi componenti.
Clienti dell'alveare:
Includono l'applicazione Thrift per eseguire comandi hive facili che sono disponibili per python, ruby, C ++ e driver. Questi vantaggi dell'applicazione client per l'esecuzione di query sull'hive. Hive ha tre tipi di categorizzazione client: client di risparmio, client JDBC e ODBC.
Servizi alveare:
Per elaborare tutte le query hive ha vari servizi. Tutte le funzioni sono facilmente definite dall'utente nell'alveare. Vediamo in breve tutti quei servizi:
- Interfaccia della riga di comando ( interfaccia utente): consente l'interazione tra l'utente e l'hive, una shell predefinita. Fornisce una GUI per l'esecuzione della riga di comando hive e hive insight. Possiamo anche utilizzare le interfacce Web (HWI) per inviare le query e le interazioni con un browser Web.
- Driver Hive: riceve query da diverse fonti e client come il server dell'usato e memorizza e recupera su driver ODBC e JDBC che sono automaticamente collegati all'alveare. Questo componente esegue un'analisi semantica sulla visualizzazione delle tabelle dal metastore che analizza una query. Il driver prende l'aiuto del compilatore ed esegue funzioni come un parser, Planner, Esecuzione di lavori MapReduce e ottimizzatore.
- Compilatore: l' analisi e il processo semantico della query vengono eseguiti dal compilatore. Converte la query in un albero di sintassi astratto e di nuovo in DAG per compatibilità. L'ottimizzatore, a sua volta, divide le attività disponibili. Il compito dell'esecutore è eseguire le attività e monitorare la pianificazione della pipeline delle attività.
- Motore di esecuzione: tutte le query vengono elaborate da un motore di esecuzione. I piani di fase di un DAG vengono eseguiti dal motore e aiutano a gestire le dipendenze tra le fasi disponibili ed eseguirle su un componente corretto.
- Metastore: funge da repository centrale per archiviare tutte le informazioni strutturate dei metadati, inoltre è un aspetto importante per l'alveare in quanto contiene informazioni come tabelle e dettagli di partizionamento e l'archiviazione dei file HDFS. In altre parole, diremo che metastore funge da spazio dei nomi per le tabelle. Metastore è considerato un database separato condiviso anche da altri componenti. Metastore ha due pezzi chiamati service e backlog storage.
Il modello di dati hive è strutturato in partizioni, bucket, tabelle. Tutti questi possono essere filtrati, avere chiavi di partizione e valutare la query. La query Hive funziona sul framework Hadoop, non sul database tradizionale. Il server hive è un'interfaccia tra un client remoto che esegue query sull'hive. Il motore di esecuzione è completamente incorporato in un server hive. È possibile trovare applicazioni hive nell'apprendimento automatico, nella business intelligence nel processo di rilevamento.
Flusso di lavoro dell'alveare:
Hive funziona in due tipi di modalità: modalità interattiva e modalità non interattiva. La modalità precedente consente a tutti i comandi hive di passare direttamente alla shell hive mentre il tipo successivo esegue il codice in modalità console. I dati sono divisi in partizioni che si suddividono ulteriormente in bucket. I piani di esecuzione si basano su aggregazione e inclinazione dei dati. Un ulteriore vantaggio dell'utilizzo di hive è che elabora facilmente grandi quantità di informazioni e ha più interfacce utente.
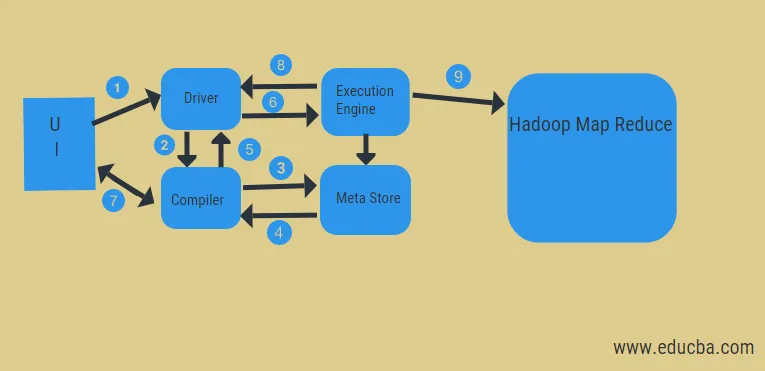
Dal diagramma sopra, possiamo vedere il flusso di dati nell'alveare con il sistema Hadoop.
I passaggi includono:
- eseguire la query dall'interfaccia utente
- ottenere un piano dalle fasi DAG delle attività del conducente
- ottenere la richiesta di metadati dal meta store
- invia metadati dal compilatore
- rispedendo il piano al conducente
- Eseguire il piano nel motore di esecuzione
- recupero dei risultati per la query dell'utente appropriata
- invio di risultati bidirezionali
- elaborazione del motore di esecuzione in HDFS con riduzione della mappa e recupero dei risultati dai nodi di dati creati dal job tracker. funge da connettore tra Hive e Hadoop.
Il compito del motore di esecuzione è comunicare con i nodi per ottenere le informazioni memorizzate nella tabella. Qui vengono eseguite operazioni SQL come create, drop, alter per accedere alla tabella.
Conclusione:
Abbiamo esaminato l'architettura Hive e il loro flusso di lavoro, hive esegue sostanzialmente una piccola quantità di dati e quindi è un pacchetto di data warehouse sulla piattaforma Hadoop. Poiché hive è una buona scelta per gestire un volume di dati elevato, aiuta nella preparazione dei dati con la guida dell'interfaccia SQL per risolvere i problemi di MapReduce. Apache hive è uno strumento ETL per elaborare dati strutturati. Conoscere il funzionamento dell'architettura dell'alveare aiuta le persone aziendali a comprendere il funzionamento principale dell'alveare e ha un buon inizio con la programmazione dell'alveare.
Articoli consigliati:
Questa è stata una guida per Hive Architecture. Qui discutiamo l'architettura dell'alveare, i diversi componenti e il flusso di lavoro dell'alveare. puoi anche consultare i seguenti articoli per saperne di più-
- Architettura di Hadoop
- Usi Di Rubino
- Cos'è il C ++
- Cos'è il database MySQL
- Hive Order di